
【版权声明】版权所有,严禁转载,严禁用于商业用途,侵权必究。
作者:厦门大学信息学院2020级研究生 寿铁祺
指导老师:厦门大学数据库实验室 林子雨 博士/副教授
相关教材:林子雨、陶继平编著《Flink编程基础(Scala版)》(官网)
相关案例:基于Scala语言的Flink数据处理分析案例集锦
本实验爬取了豆瓣电影的31441条电影记录,使用scala语言进行flink编程处理了数据,最后结果使用python进行了可视化
一、 实验环境:
1 系统:Ubuntu 18.04
2 编程语言:Scala 2.12.13,Python 3.7.7
3 Java环境:JDK 1.8.0_162
4 框架:Flink-1.11.2,Hadoop-3.1.3,Maven-3.6.3
5 Python包:Pandas,Plotly
6 开发工具:Idea-2020.2.3,Jupyter Notebook
其中的绝大部分环境都可按照课堂PPT和官网资料安装配置,额外的Python包可通过以下命令安装:
Pandas:pip install pandas
Plotly:pip install plotly
本实验涉及到的所有数据集和代码,可以从百度网盘下载。
链接:https://pan.baidu.com/s/1NjznWRlJw5HIywo3JEdbig
提取码:ziyu
二、 实验数据集:
1. 数据集说明:
本次实验采用的数据于2019年3月从豆瓣电影(https://movie.douban.com/)上爬取,包含31441条电影记录。每条记录包含以下字段:
1) id:一串整数,标识网页链接的后缀。
2) name:电影名。
3) year:上映年份。
4) ratingsum:评分人数。
5) genre:电影类型。
6) country:制片国家/地区。
数据集预览:

图2.1 数据集预览
2.将数据集存放在分布式文件系统HDFS中:
A. 启动Hadoop中的HDFS组件,在命令行运行下面命令:
/usr/local/hadoop/sbin/start-dfs.sh
B. 在hadoop上登录用户创建目录,在命令行运行下面命令:
hdfs dfs -mkdir -p /user/hadoop
C. 把本地文件系统中的数据集albums.csv上传到分布式文件系统HDFS中:
hdfs dfs -put douban_2.csv
三、 使用 Flink进行数据分析:
主要完成以下几个分析任务:
1 每个年份的电影数
2 每个评分区间的电影数
3 每个制片地区的电影数
4 每个制片地区电影的平均评分
5 每种类型的电影数
6 每种类型电影的平均评分
1. 创建idea工程:
(1) 打开Linux终端,输入以下命令启动idea:
/usr/local/idea/bin/idea.sh
选择新建项目,并创建Maven项目,如下:
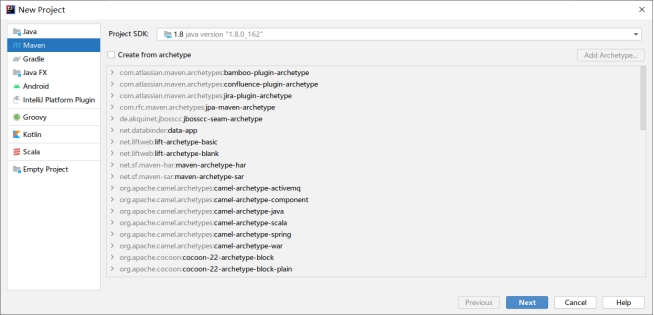
图3.1 新建Maven项目
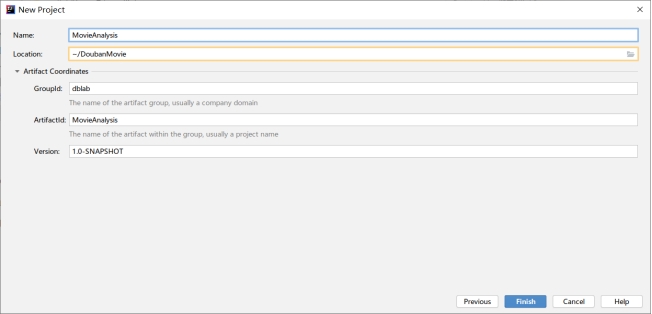
图3.2 填写项目信息
(2)初次使用请先下载Scala插件并启用:
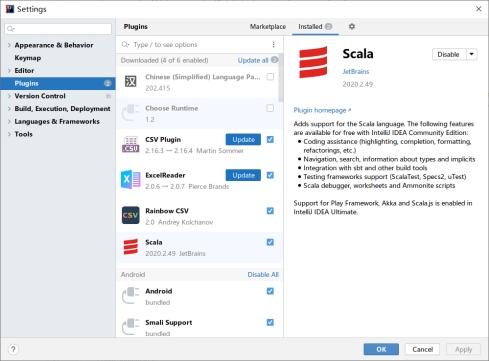
图3.3 安装启用Scala插件
(3)然后为项目添加框架支持,在项目名称“MovieAnalysis”上点击鼠标右键,在弹出的子菜单中选择“Add Framework Support”:
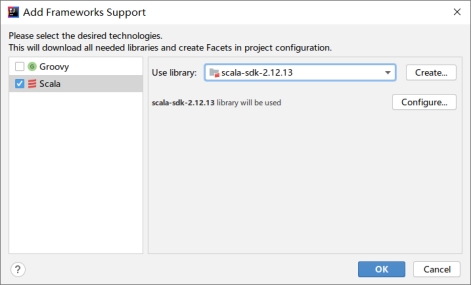
图3.4 添加框架支持
(4)修改pom.xml如下:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>dblab</groupId>
<artifactId>MovieAnalysis</artifactId>
<version>1.0-SNAPSHOT</version>
<repositories>
<repository>
<id>alimaven</id>
<name>aliyun maven</name>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_2.12</artifactId>
<version>1.11.2</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.12</artifactId>
<version>1.11.2</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.12</artifactId>
<version>1.11.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.1.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.3</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.4.6</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
(5)在项目DoubanMovie/src/main/java目录上单击鼠标右键,在弹出的菜单中选择“New”,再在弹出的菜单中选择“Scala Class”,然后,在弹出的界面中,输入类的名称“movieAnalyze”,类型选择“Object”,然后回车,就可以创建一个空的代码文件movieAnalyze.scala。
图3.5 新建代码文件

图3.6 创建Scala单例对象
2. 进行数据统计分析:
首先读取保存到HDFS上的文件:
/*读取HDFS上的数据集*/
val inputHDFS: DataSet[movie] = env.readCsvFile[movie]("hdfs://localhost:9000/user/hadoop/douban_2.csv", ignoreFirstLine = true)
接下来逐个完成数据统计:
(1) 每个年份的电影数
/*统计每个年份的电影数*/
val yearL = inputHDFS.map(x => (x.year, 1) ) //抽取每条电影记录的年份
val yearNum = yearL.groupBy(0).sum(1) //按年份分组并计数
yearNum.writeAsCsv("file:///home/hadoop/Output/yearNum.csv") //将结果写至本地文件
(2) 每个评分区间的电影数
以1分为区间步长分别统计[1,10]分每个区间段的电影数。
/*统计每个评分区间的电影数*/
val ratingNum_L = new ArrayBuffer[(String, Int)]() //先建立数组用于保存结果
for(i <- 1 to 9){ //对1-9分区间的电影数目进行循环统计
val tmp = inputHDFS.filter(_.rating.toString.startsWith(i.toString + '.')) //筛选出[i, i+1)分区间的电影
ratingNum_L.append((i.toString, tmp.collect().size)) //将本区间段的电影数目保存到数组
}
val ratingNum = env.fromCollection(ratingNum_L) //将数组类型转换成DataSet类型
ratingNum.writeAsCsv("file:///home/hadoop/Output/ratingNum.csv") //将结果写至本地文件
(3) 每个制片地区的电影数
/*统计每个制片地区的电影数*/
val filmCountry_L = inputHDFS.map(x => (x.country.split('/')(0), 1)) //将首要制片地区提取出来
val filmCountryNum = filmCountry_L.groupBy(0).sum(1) //对制片地区分组计数
val filmCountryNum_Sort = filmCountryNum.sortPartition(1, Order.DESCENDING) //对统计结果降序排序
filmCountryNum_Sort.writeAsCsv("file:///home/hadoop/Output/filmCountryNum_Sort.csv") //将结果写至本地文件
(4) 每个制片地区电影的平均评分
/*统计每个制片地区电影的平均评分*/
val filmCountry_rating_c = inputHDFS.map(x => (x.country.split('/')(0), x.rating)) //提取制片地区和评分
val filmCountry_rating_sum = filmCountry_rating_c.groupBy(0).sum(1) //统计制片地区的电影总评分
val filmCountry_ratingAverage = filmCountry_rating_sum.join(filmCountryNum).where(0).equalTo(0){ //将制片地区的总评分表和总电影数表合并
(left, right) => (left._1, left._2 / right._2) //用总评分/总电影数计算平均得分
}
val filmCountry_ratingAverage_Sort = filmCountry_ratingAverage.sortPartition(1, Order.DESCENDING) //降序排序
filmCountry_ratingAverage_Sort.writeAsCsv("file:///home/hadoop/Output/filmCountry_ratingAverage_Sort.csv") //将结果写至本地文件
(5) 每种类型的电影数
/*统计每种类型的电影数*/
val filmGenres = inputHDFS.flatMap(x => x.genre.split('/')) //将每部电影的所属的多个类型展开
val filmGenres_L = filmGenres.collect().toList //所属类型由DataSet转List,方便后续操作
val genres_L = filmGenres.map(x => (x, 1))
val genres_num = genres_L.groupBy(0).sum(1) //对所属类型计数得到结果
val genres_num_Sort = genres_num.sortPartition(1, Order.DESCENDING) //降序排序
genres_num_Sort.writeAsCsv("file:///home/hadoop/Output/genres_num_Sort.csv") //将结果写至本地文件
(6) 每种类型电影的平均评分
/*统计每种类型电影的平均评分*/
val filmGenre_num = inputHDFS.map(x => x.genre.split('/').size) //记录每部电影的所属类型有多少个
val filmGenre_num_L = filmGenre_num.collect().toList //所属类型数目由DataSet转List,方便后续操作
val filmRating = inputHDFS.map(x => x.rating) //记录每部电影的评分
val filmRating_L = filmRating.collect().toList //评分由DataSet转List,方便后续操作
val genresRatings = new ArrayBuffer[(String, Double)]() //先建立数组用以记录展开后每个类型的评分
var idx = 0 //指针
for(i <- 0 until filmRating_L.size){ //对每一部电影,按照所属类型的个数将评分分配若干次至展开的类型数组
val the_genre_num = filmGenre_num_L(i) //提取第i部电影的类型数目
val the_rating = filmRating_L(i) //提取第i部电影的评分
for(j <- 0 until the_genre_num){ //循环分配评分给展开的类型数组
genresRatings.append((filmGenres_L(idx + j), the_rating))
}
idx = idx + the_genre_num //更新指针
}
val genresRatings_Dataset = env.fromCollection(genresRatings) //将得到的数组转DataSet
val genreRating_sum = genresRatings_Dataset.groupBy(0).sum(1) //分组计算每种类型电影的总评分
val genres_ratingAverage = genreRating_sum.join(genres_num).where(0).equalTo(0){ //将每种类型的总评分表和总电影数表合并
(left, right) => (left._1, left._2 / right._2) //用总评分/总电影数计算平均评分
}
val genres_ratingAverage_Sort = genres_ratingAverage.sortPartition(1, Order.DESCENDING) //降序排序
genres_ratingAverage_Sort.writeAsCsv("file:///home/hadoop/Output/genres_ratingAverage_Sort.csv") //将结果写至本地文件
汇总以上代码得到movieAnalyze.scala:
import org.apache.flink.api.common.operators.Order
import org.apache.flink.api.scala.{DataSet, ExecutionEnvironment, _}
import scala.collection.mutable.ArrayBuffer
object movieAnalyze {
def main(args: Array[String]): Unit = {
val env = ExecutionEnvironment.getExecutionEnvironment //建立执行环境
env.setParallelism(1)
/*读取HDFS上的数据集*/
val inputHDFS: DataSet[movie] = env.readCsvFile[movie]("hdfs://localhost:9000/user/hadoop/douban_2.csv", ignoreFirstLine = true)
/*统计每个年份的电影数*/
val yearL = inputHDFS.map(x => (x.year, 1) ) //抽取每条电影记录的年份
val yearNum = yearL.groupBy(0).sum(1) //按年份分组并计数
yearNum.writeAsCsv("file:///home/hadoop/Output/yearNum.csv") //将结果写至本地文件
/*统计每个评分区间的电影数*/
val ratingNum_L = new ArrayBuffer[(String, Int)]() //先建立数组用于保存结果
for(i <- 1 to 9){ //对1-9分区间的电影数目进行循环统计
val tmp = inputHDFS.filter(_.rating.toString.startsWith(i.toString + '.')) //筛选出[i, i+1)分区间的电影
ratingNum_L.append((i.toString, tmp.collect().size)) //将本区间段的电影数目保存到数组
}
val ratingNum = env.fromCollection(ratingNum_L) //将数组类型转换成DataSet类型
ratingNum.writeAsCsv("file:///home/hadoop/Output/ratingNum.csv") //将结果写至本地文件
/*统计每个制片地区的电影数*/
val filmCountry_L = inputHDFS.map(x => (x.country.split('/')(0), 1)) //将首要制片地区提取出来
val filmCountryNum = filmCountry_L.groupBy(0).sum(1) //对制片地区分组计数
val filmCountryNum_Sort = filmCountryNum.sortPartition(1, Order.DESCENDING) //对统计结果降序排序
filmCountryNum_Sort.writeAsCsv("file:///home/hadoop/Output/filmCountryNum_Sort.csv") //将结果写至本地文件
/*统计每个制片地区电影的平均评分*/
val filmCountry_rating_c = inputHDFS.map(x => (x.country.split('/')(0), x.rating)) //提取制片地区和评分
val filmCountry_rating_sum = filmCountry_rating_c.groupBy(0).sum(1) //统计制片地区的电影总评分
val filmCountry_ratingAverage = filmCountry_rating_sum.join(filmCountryNum).where(0).equalTo(0){ //将制片地区的总评分表和总电影数表合并
(left, right) => (left._1, left._2 / right._2) //用总评分/总电影数计算平均得分
}
val filmCountry_ratingAverage_Sort = filmCountry_ratingAverage.sortPartition(1, Order.DESCENDING) //降序排序
filmCountry_ratingAverage_Sort.writeAsCsv("file:///home/hadoop/Output/filmCountry_ratingAverage_Sort.csv") //将结果写至本地文件
/*统计每种类型的电影数*/
val filmGenres = inputHDFS.flatMap(x => x.genre.split('/')) //将每部电影的所属的多个类型展开
val filmGenres_L = filmGenres.collect().toList //所属类型由DataSet转List,方便后续操作
val genres_L = filmGenres.map(x => (x, 1))
val genres_num = genres_L.groupBy(0).sum(1) //对所属类型计数得到结果
val genres_num_Sort = genres_num.sortPartition(1, Order.DESCENDING) //降序排序
genres_num_Sort.writeAsCsv("file:///home/hadoop/Output/genres_num_Sort.csv") //将结果写至本地文件
/*统计每种类型电影的平均评分*/
val filmGenre_num = inputHDFS.map(x => x.genre.split('/').size) //记录每部电影的所属类型有多少个
val filmGenre_num_L = filmGenre_num.collect().toList //所属类型数目由DataSet转List,方便后续操作
val filmRating = inputHDFS.map(x => x.rating) //记录每部电影的评分
val filmRating_L = filmRating.collect().toList //评分由DataSet转List,方便后续操作
val genresRatings = new ArrayBuffer[(String, Double)]() //先建立数组用以记录展开后每个类型的评分
var idx = 0 //指针
for(i <- 0 until filmRating_L.size){ //对每一部电影,按照所属类型的个数将评分分配若干次至展开的类型数组
val the_genre_num = filmGenre_num_L(i) //提取第i部电影的类型数目
val the_rating = filmRating_L(i) //提取第i部电影的评分
for(j <- 0 until the_genre_num){ //循环分配评分给展开的类型数组
genresRatings.append((filmGenres_L(idx + j), the_rating))
}
idx = idx + the_genre_num //更新指针
}
val genresRatings_Dataset = env.fromCollection(genresRatings) //将得到的数组转DataSet
val genreRating_sum = genresRatings_Dataset.groupBy(0).sum(1) //分组计算每种类型电影的总评分
val genres_ratingAverage = genreRating_sum.join(genres_num).where(0).equalTo(0){ //将每种类型的总评分表和总电影数表合并
(left, right) => (left._1, left._2 / right._2) //用总评分/总电影数计算平均评分
}
val genres_ratingAverage_Sort = genres_ratingAverage.sortPartition(1, Order.DESCENDING) //降序排序
genres_ratingAverage_Sort.writeAsCsv("file:///home/hadoop/Output/genres_ratingAverage_Sort.csv") //将结果写至本地文件
env.execute("Write Results to local files!") //执行写入操作
}
}
case class movie(id:Long, name:String, year:Int, rating:Double, ratingsum:Long, genre:String, country:String) //建立movie类来接收来自文件的记录
运行以上代码可得到实验结果,存放在/home/Hadoop/Output目录下:

图3.7 查看统计结果目录
四、 实验结果可视化:
本实验的可视化工具采用plotly,它支持绘制可交互的图表,并完美兼容Jupyter Notebook(查看Jupyter Notebook可以体验图表的交互效果)。
1 每个年份的电影数
先导入用到的两个包,然后读取之前生成的结果,由于2019年的数据不完整,所以暂时不考虑,调用plotly的接口绘制图表。
import pandas as pd
import plotly.express as px
yearNum = pd.read_csv("../Output/yearNum.csv", header=None)
yearNum.columns = ["year", "Num"]
yearNum = yearNum[:-1] #2019年只有前两月多的数据,不考虑
fig1 = px.bar(yearNum,
x = "year",
y = "Num",
title = "1900至2018年的电影数",
color='Num'
)
fig1.show()
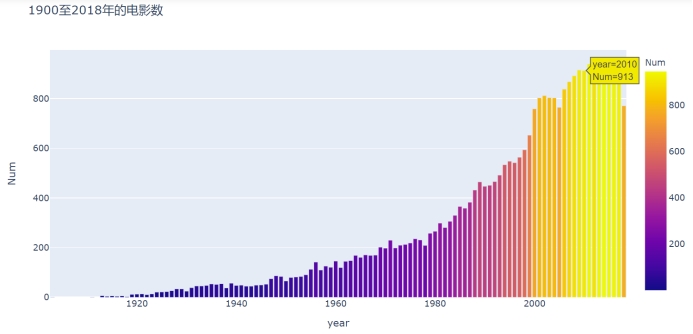
图4.1 1900至2018年地电影数目变化的条形图
从该数据集中可以观察到,自上世纪初起,生产的电影数基本呈现逐年增加的趋势,到本世纪初,达到一个高峰并且呈现稳定趋势。
2 每个评分区间的电影数
ratingNum = pd.read_csv("../Output/ratingNum.csv", header=None)
ratingNum.columns = ["rating_from", "Num"]
fig2 = px.pie(ratingNum,
values = "Num",
names = "rating_from",
title = "各个评分区间的电影数"
)
fig2.show()
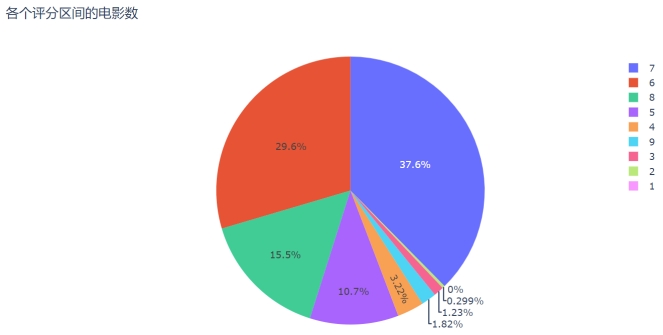
图4.2 各个评分区间电影数目占比的饼图
图例中的“1”表示[1,2)评分区间段,其余类似。从饼图中可以看出电影评分占比7分区间最多,其次是6分段,再次是8分和5分段。高于9分的佳作和低于5分的烂片占比均较少。
3 每个制片地区的电影数和平均评分
先把两张表合并,然后绘制电影数目前25位散点图。
filmCountryNum_Sort = pd.read_csv("../Output/filmCountryNum_Sort.csv", header=None)
filmCountryNum_Sort.columns = ["area", "Num"]
filmCountry_ratingAverage_Sort = pd.read_csv("../Output/filmCountry_ratingAverage_Sort.csv", header=None)
filmCountry_ratingAverage_Sort.columns = ["area", "Average_Rating"]
countryNum_avergeRating = pd.merge(filmCountryNum_Sort, filmCountry_ratingAverage_Sort, on='area') #合并两表
fig3 = px.scatter(countryNum_avergeRating[:25], x="Num", y="Average_Rating", #展示电影数前25位的制片地区的电影数目和均分的散点图
color="area",
hover_name="area",
title="各制片地区电影数和平均评分关系")
fig3.show()
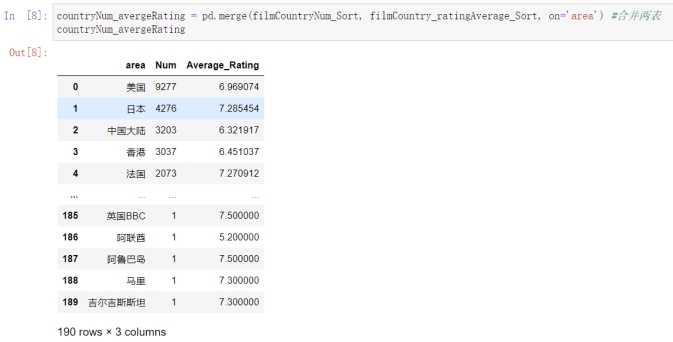
图4.3 合并制片地区的电影数目和平均评分表
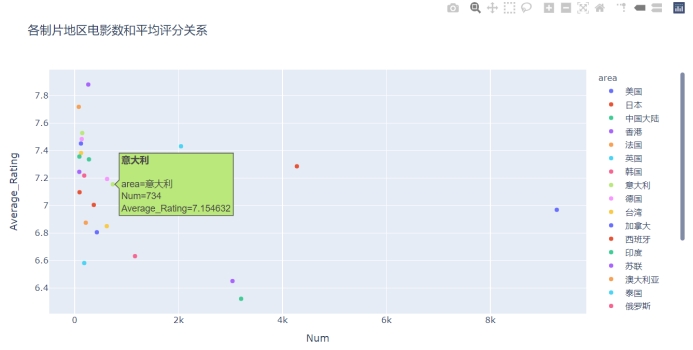
图4.4 电影数前25位的制片地区的电影数和平均评分的关系的散点图
为了增加展示维度,再绘制电影数前15位的情况的气泡图,以地区作为x轴,电影数量“Num”表示气泡大小。
fig4 = px.scatter(countryNum_avergeRating[:15], x="area", y="Average_Rating",
size="Num", color = "area",
hover_name="area", title="各制片地区电影数和平均评分")
fig4.show()
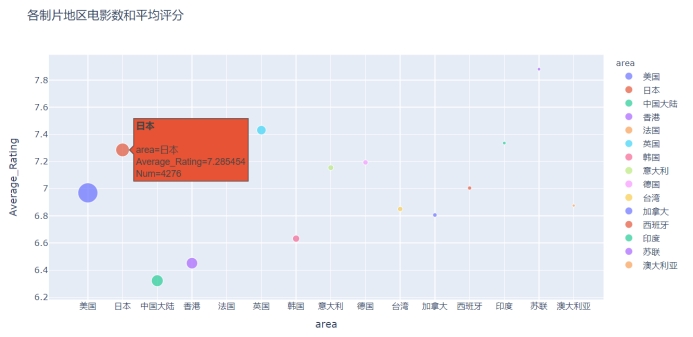
图4.5 电影数前15位的制片地区的电影数和平均评分情况的气泡图
从以上图表中可以看出,电影数目是美国、日本、中国大陆、中国香港、法国居于Top 5,从均分上来看,日本和法国的电影评价较好,较受豆瓣观众的喜爱,国产的电影总体均分较低。
4 每种类型的电影数
genres_num_Sort = pd.read_csv("../Output/genres_num_Sort.csv", header=None)
genres_num_Sort.columns = ["genre", "Num"]
fig5 = px.bar(genres_num_Sort,
x = "genre",
y = "Num",
title = "各类型电影数",
color='Num'
)
fig5.show()
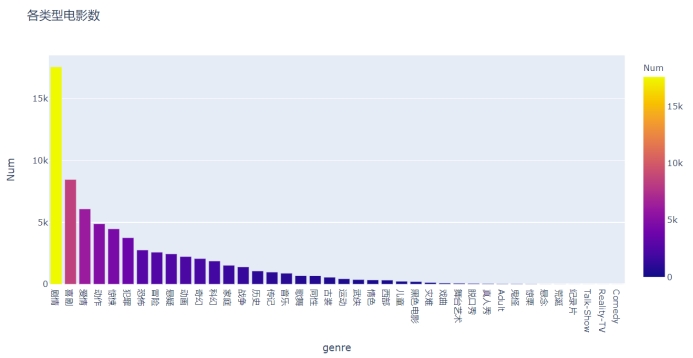
图4.6 各类型电影数目的条形图
从图上可以看出,电影数量位居前10的电影类型分别是剧情、喜剧、爱情、动作、惊悚、犯罪、恐怖、冒险、悬疑、动画。其中,“剧情”类型标签占比相当大。
5 每种类型电影的平均评分和电影数
genres_ratingAverage_Sort = pd.read_csv("../Output/genres_ratingAverage_Sort.csv", header=None)
genres_ratingAverage_Sort.columns = ["genre", "Average_Rating"]
genreNum_avergeRating = pd.merge(genres_num_Sort, genres_ratingAverage_Sort, on='genre') #两表合并
fig6 = px.scatter(genreNum_avergeRating, x="Num", y="Average_Rating",
color="genre",
hover_name="genre",
title = "各类型电影数和平均评分关系"
)
fig6.show()

图4.7 各类型电影数和平均评分关系的散点图
可以看出电影数目最多的几个类型均分都在7分左右,而数量少的类型电影的均分分布有高有低。
为了从不同的角度加以展示,再绘制以类型作为x轴,电影数量“Num”表示气泡大小的气泡图。
fig7 = px.scatter(genreNum_avergeRating, x="genre", y="Average_Rating",
size="Num", color = "genre",
hover_name="genre",
title = "各类型电影数和平均评分")
fig7.show()
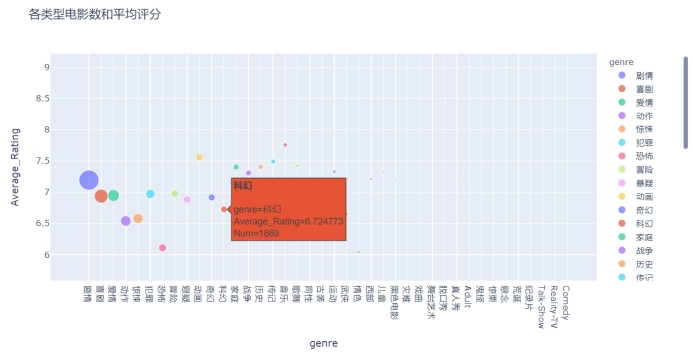
图4.8 各类型电影数和平均评分的气泡图
从图中可以更直观地看出类型的均分情况。
提示:想要更完整地体验可视化效果,请自行查阅Jupyter Notebook。