
文章结构
- TensorFlow相关介绍
- TensorFlow的安装使用(入门级)
1.关于TensorFlow
TensorFlow是一个采用数据流图(data flow graphs),用于数值计算的开源软件库。节点(Nodes)在图中表示数学操作,图中的(edges)则表示在节点间相互联系的多维数据数组,即张量(tensor)。它灵活的架构让你可以在多种平台上展开计算,例如台式计算机中的一个或多个CPU(或GPU),服务器,移动设备等等。TensorFlow 最初Google大脑小组(隶属于Google机器智能研究机构)的研究员和工程师们开发出来,用于机器学习和深度神经网络方面的研究,但这个系统的通用性使其也可广泛用于其他计算领域。
1.1什么是数据流图(Data Flow Graph)?
数据流图用“结点”(nodes)和“线”(edges)的有向图来描述数学计算。“节点” 一般用来表示施加的数学操作,但也可以表示数据输入(feed in)的起点/输出(push out)的终点,或者是读取/写入持久变量(persistent variable)的终点。“线”表示“节点”之间的输入/输出关系。这些数据“线”可以输运“size可动态调整”的多维数据数组,即“张量”(tensor)。张量从图中流过的直观图像是这个工具取名为“Tensorflow”的原因。一旦输入端的所有张量准备好,节点将被分配到各种计算设备完成异步并行地执行运算。
1.2TensorFLow 六大特性
1.高度的灵活性----提供很多的工具让你来构建图,也可以在tf基础上写上层库,对tf操作进行组合,还可以动手丰富底层操作,自己添加tf内容
2.真正的可移植性----tf在CPU和GPU上运行,可以运行在台式机、服务器、手机移动设备,Android,ios都可以,平台之间转移可以不用改
3.将科研和产品联系在一起----tf可以免去很大的代码重写工作,帮助科研工作者提高科研产出率
4.自动求微分----用户只需要定义预测模型的结构,将这个结构和目标函数结合在一起,并添加数据,tf将自动为你计算相关的微分导数
5.多语言支持----官方文档中写明,目前有python/c++使用界面,还鼓励开发者开发其他语言
6.性能最优化----给予了线程、队列、异步操作等以最佳支持,tf让你可以将你手边硬件的计算潜能全部发挥出来。你可以自由地将tf图中的计算元素分配到不同设备上,tf可以帮你管理好这些不同副本
1.3TensorFLow三个有趣的应用案例
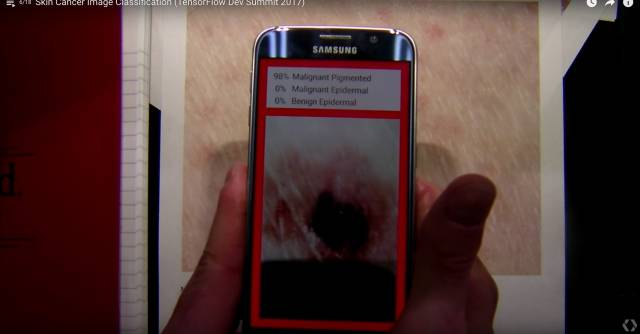
1.皮肤癌图像分类
相关成果发表在Nature,而且在Nature的封面,这是一个特别成功地通过计算机视觉及深度学习相关的技术,利用廉价的移动设备,能够很有效地检测是否有皮肤癌,大大节省了医疗检测的成本
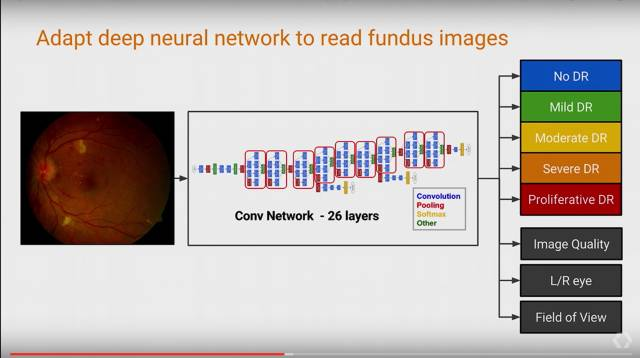
2.利用AI预测糖尿病,预防失明
通过收集适量的医疗数据,构建一个26layers的深度卷积网络,可以让网络自动学习这些图像中的feature,来获得较高的分类准确率,而这个是人眼很难解决的。
模型最后的评估比专业医生对比,F-score为0.95,比专业医生的中位数0.91还高.
3.自动控制数据中心冷却设备
DeepMind在被Google收购之后,也选择TensorFlow作为其深度学习相关研究的平台 . AlphaGo由该团队开发.
团队利用AlphaGO的强度学习技术,来做数据中心冷却设备的自动控制,并且效果十分显著.

2.TensroFlow的安装使用
2.1TensorFlow的安装
2.1.1相关依赖包安装
TensorFlow的python API依赖python2.7版本,所以我们要先安装python以及pip.
安装方法如下.
打开终端,输入以下命令来安装相关软件包.
#python安装
sudo apt-get install python2.7 python2.7-dev
#pip安装
sudo apt-get install python-pip python-dev build-essential
2.1.2TensorFlow安装
TensorFlow有cpu版本跟gpu版本的安装,但是我们的电脑没有独显,所以为了让我们可以继续学习如何使用,我们安装cpu版本的.
但是由于下载地址需要翻墙,所以这里我们提供安装包.https://pan.baidu.com/s/1eSfbqP8
这个安装里包含0.9版本的TensorFlow,以及本教程将会用到的几个代码.
解压下载下来的压缩包,打开文件所在文件夹,然后运行如下命令进行安装.
sudo pip install ./tensorflow-0.5.0-cp27-none-linux_x86_64.whl
2.1.3测试安装是否成功
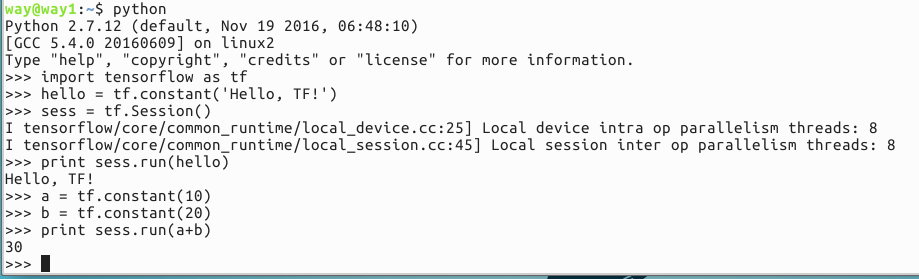
打开终端,运行python shell,按照下图输入代码.

做一个代码的简要分析:
>>> import tensorflow as tf #tensorflow是API,需要导入包
>>> hello = tf.constant('hello,TF') #创建一个hello常量
>>> sess = tf.Sesssion()
>>> print sess.run(hello)#要使用seesion才可以真正实例化对象
>>> #后面的代码就不多解释了
我们可以从下图的测试效果中看到,tf对于资源的利用情况,我的cpu是4核心8线程
2.2TensorFlow的使用---MNIST初级入门
接下来我们将通过一个实例的方式来了解一下TF.
MNIST是一个入门级的计算机视觉数据集,它包含如下各种手写数字图片:
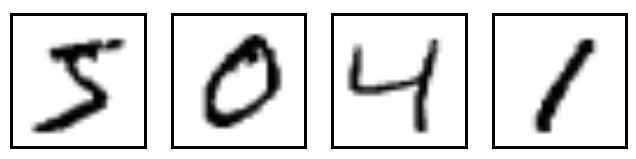
接下来我们将训练一个机器学习模型用于预测图片里面的数字. MNIST数据集的官网是Yann LeCun's website(翻墙)。官方文档提供了一份python源代码(input_data.py)用于自动下载和安装这个数据集. 这个代码也是需要翻墙的所以,请使用之前下好的代码.
2.2.1下载数据集
我们先来看看input_data.py做了什么.
1.maybe_download() 函数可以确保这些训练数据下载到本地文件夹中.

2.下载好的文件本身并没有使用标准的图片格式储存,并且需要使用input_data.py文件中extract_images() 和extract_labels()函数来手动解压.图片数据将被解压成2维的tensor:[image index, pixel index], "image index"代表数据集中图片的编号, 从0到数据集的上限值。"pixel index"代表该图片中像素点得个数, 从0到图片的像素上限值。以train-*开头的文件中包括60000个样本,其中分割出55000个样本作为训练集,其余的5000个样本作为验证集。因为所有数据集中28x28像素的灰度图片的尺寸为784,所以训练集输出的tensor格式为[55000, 784]。
数字标签数据被解压称1维的tensor: [image index],它定义了每个样本数值的类别分类。对于训练集的标签来说,这个数据规模就是:[55000]。
3.input_data.py的read_data_sets()会返回一个实例包含以下三组数据集:
| 数据集 | 目的 |
|---|---|
| data_sets.train | 55000 组 图片和标签, 用于训练。 |
| data_sets.validation | 5000 组 图片和标签, 用于迭代验证训练的准确性。 |
| data_sets.test | 10000 组 图片和标签, 用于最终测试训练的准确性。 |
函数DataSet.next_batch()是用于获取以batch_size为大小的一个元组,其中包含了一组图片和标签,该元组会被用于当前的TensorFlow运算会话中。调用如下:
images_feed, labels_feed = data_set.next_batch(FLAGS.batch_size)
input_data.py的使用方法
导入input_data.py,并调用read_dataset()函数
import input_data
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
2.2.2数据集介绍
每一个MNIST数据单元有两部分组成:一张包含手写数字的图片和一个对应的标签。我们把这些图片设为“xs”,把这些标签设为“ys”。训练数据集和测试数据集都包含xs和ys,比如训练数据集的图片是 mnist.train.images ,训练数据集的标签是 mnist.train.labels。每一张图片包含28像素X28像素。我们可以用一个数字数组来表示这张图片:
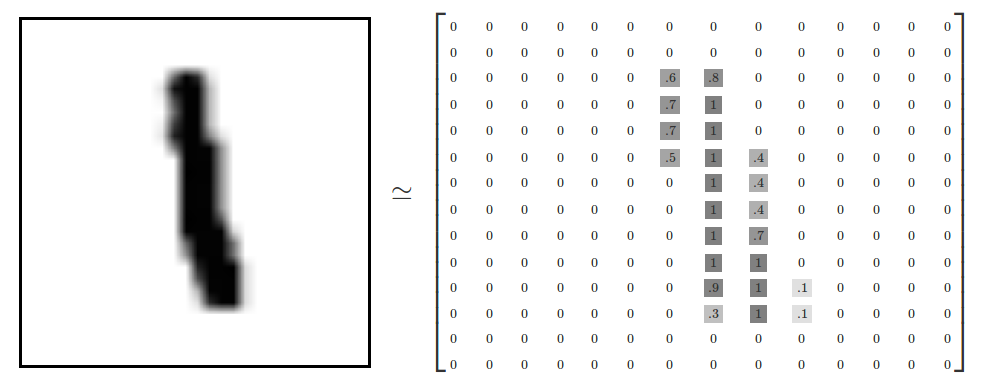
在MNIST训练数据集中,mnist.train.images 是一个形状为 [60000, 784] 的张量,第一个维度数字用来索引图片,第二个维度数字用来索引每张图片中的像素点。在此张量里的每一个元素,都表示某张图片里的某个像素的强度值,值介于0和1之间。 也就是说[100,100]就表示第一百张图片的第一百个像素点.mnist.train.images大概长这样:

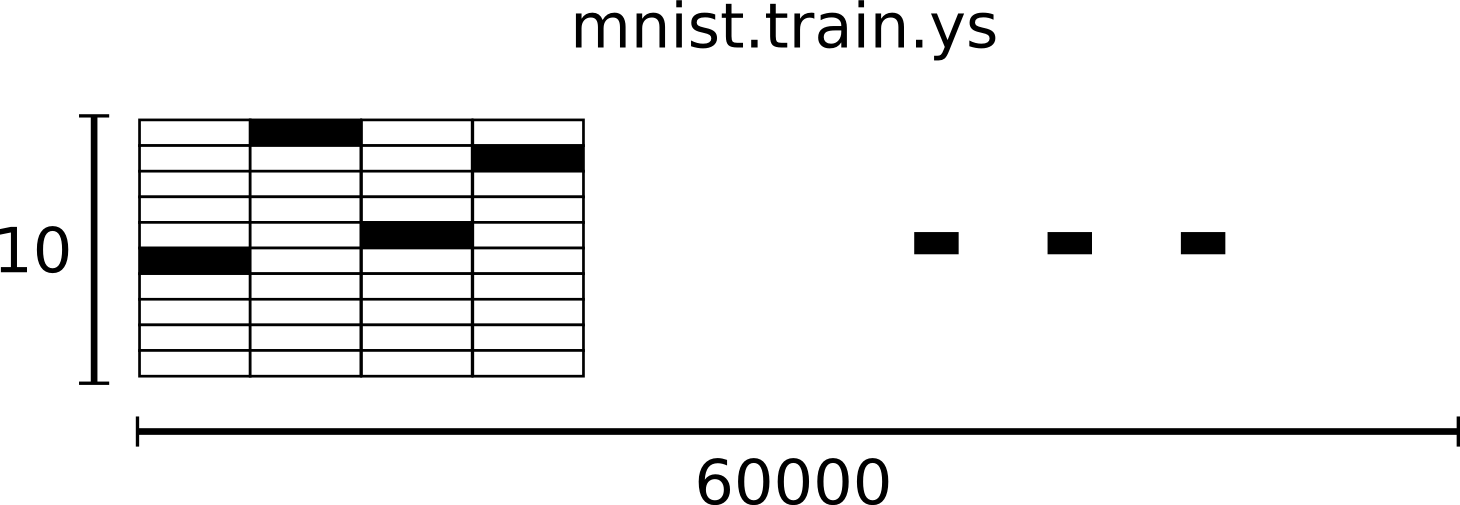
相对应的MNIST数据集的标签是介于0到9的数字,用来描述给定图片里表示的数字。为了用于这个教程,我们使标签数据是"one-hot vectors"。 一个one-hot向量除了某一位的数字是1以外其余各维度数字都是0。所以在此教程中,数字n将表示成一个只有在第n维度(从0开始)数字为1的10维向量。比如,标签0将表示成([1,0,0,0,0,0,0,0,0,0,0])。因此, mnist.train.labels 是一个 [60000, 10] 的数字矩阵。mnist.train.labels长这样:
2.3softmax模型介绍
介绍完数据集,我们再来看一下我们将要使用的机器学习模型softmax.
softmax回归是要对一个未知对象进行预测的概率分配模型.也就是说,输入一个图片x,softmax会得到x分别是0,1,2..的概率.
那么要对x进行分配概率,我们的做法就是对图片中的每一个像素进行加权求和.可以这么理解,我们一张图张开后是748个像素,那么其中的第100个像素对于不同的数字是不一样的,假设对于0,8,9,3等这些数字100号像素是有颜色的.对于1,2,4,5,等是没有颜色的,那么对于计算x是不是某个数字的时候,对于100像素点的权重就是不一样的.
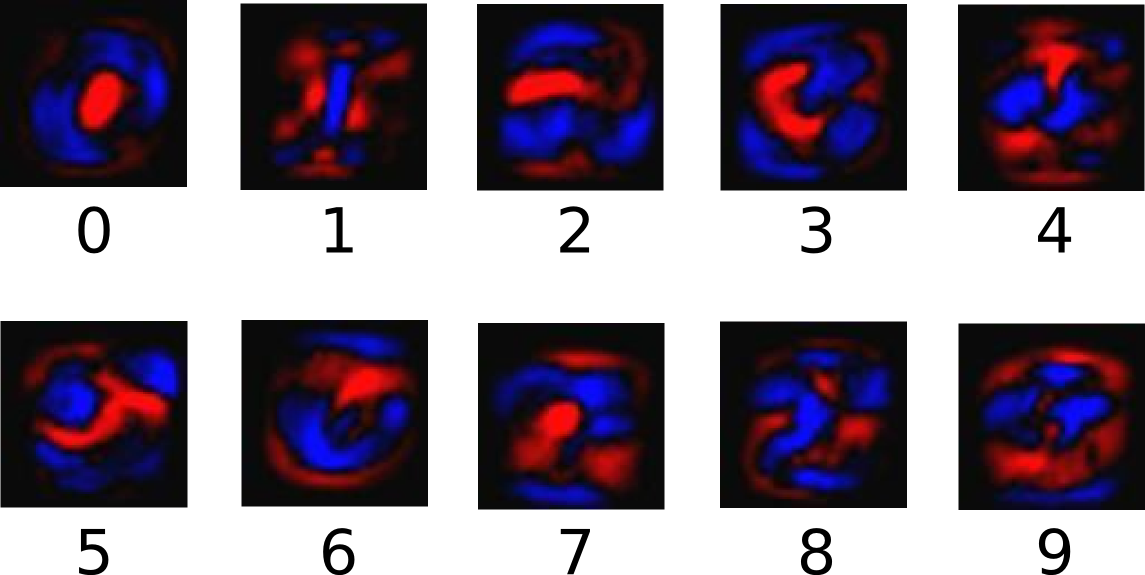
就像下图中,红色代表负权值,蓝色代表正权值:
所以经过上面的描述,一个图片是某个数字的证据(evidence)就可以表示如下:
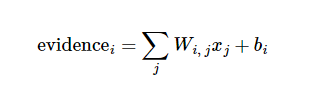
因为输入经常会带有无关的干扰,所以常规的处理方式是加入偏置量b.
上面的公式中evidencei表示x图片是数字i的证据,i从0到9. Wi,j表示第j个像素点对于X是不是数字i的权重.Xj表示像素点j.
然后用softmax函数可以把这些证据转换成概率 y:y=softmax(evidence)
softmax可以把我们定义的线性函数的输出转换成我们想要的格式,也就是关于10个数字类的概率分布。因此,给定一张图片,它对于每一个数字的吻合度可以被softmax函数转换成为一个概率值。
大多数时候softmax模型函数把输入值当成幂指数求值,再正则化这些结果值。这个幂运算表示,更大的证据对应更大的假设模型(hypothesis)里面的乘数权重值。反之,拥有更少的证据意味着在假设模型里面拥有更小的乘数系数。假设模型里的权值不可以是0值或者负值。Softmax然后会正则化这些权重值,使它们的总和等于1,以此构造一个有效的概率分布。所以等式可以写成如下:
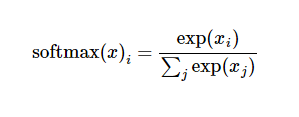
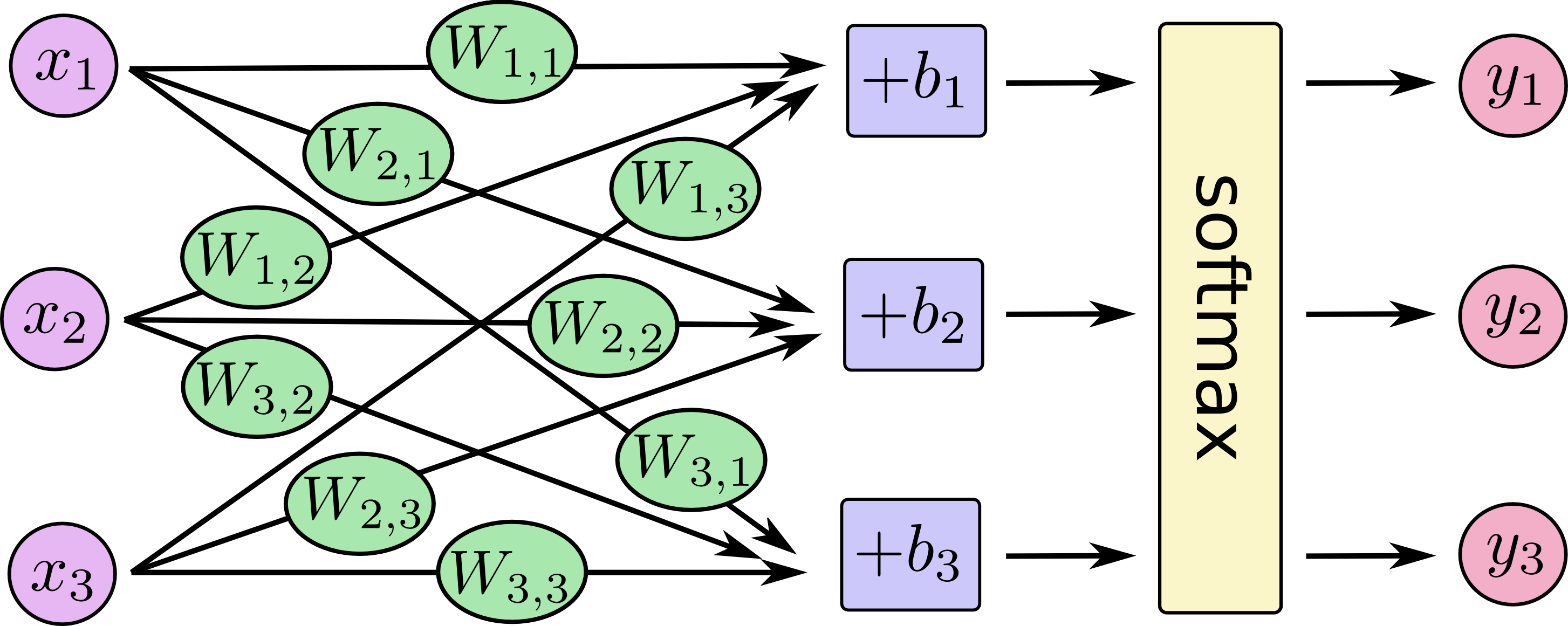
对于softmax回归模型可以用下面的图解释,对于输入的xs加权求和,再分别加上一个偏置量,最后再输入到softmax函数中:Xi是像素点,Yi是图片X是数字i的概率.
可以进一步写成矩阵的形式:
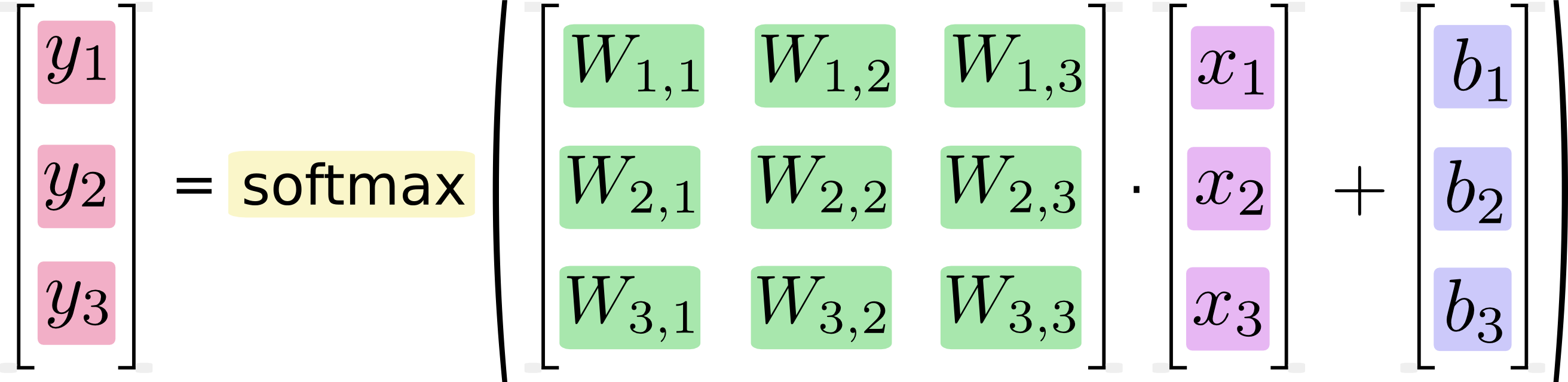
2.4具体实现
创建一个空白python文件main.py.复制粘帖以下代码.
import input_data #导入下载数据集的文件
import tensorflow as tf #导入TF
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True) #下载数据集
x = tf.placeholder("float", [None, 784]) #存储图片的可变长度变量
W = tf.Variable(tf.zeros([784,10])) #机器学习要完成的权重W变量而且初始化为0,因为这两个本来就是我们需要模型去学习训练出来的参数.
b = tf.Variable(tf.zeros([10])) #偏置量
y = tf.nn.softmax(tf.matmul(x,W) + b) #建立softmax模型,一句搞定,很简单
y_ = tf.placeholder("float", [None,10]) #真实标签数据
cross_entropy = -tf.reduce_sum(y_*tf.log(y))
train_step = tf.train.GradientDescentOptimizer(0.01).minimize(cross_entropy)
init = tf.initialize_all_variables()
sess = tf.Session()
sess.run(init)
for i in range(1000):
batch_xs, batch_ys = mnist.train.next_batch(100)
sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})
correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(y_,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
print sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels})
2.4.1学习方法
上诉代码做了部分简单的注释不多说明,其余部分可以详细说的我们单列出来.
交叉熵:cross_entropy = -tf.reduce_sum(y_*tf.log(y))
在机器学习,我们通常定义指标来表示一个模型的好坏.而交叉熵就是一个非常常见的指标.定义如下:
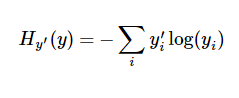
比较粗糙的理解是,交叉熵是用来衡量我们的预测用于描述真相的低效性。这个不在官方文档的描述中,不深入了.
方法:train_step = tf.train.GradientDescentOptimizer(0.01).minimize(cross_entropy)
在这里,我们要求TensorFlow用梯度下降算法(gradient descent algorithm)以0.01的学习速率最小化交叉熵。梯度下降算法(gradient descent algorithm)是一个简单的学习过程,TensorFlow只需将每个变量一点点地往使成本不断降低的方向移动。当然TensorFlow也提供了其他许多优化算法:只要简单地调整一行代码就可以使用其他的算法.
后面开始训练模型,我们让模型循环训练1000次!每次随机选取100张图输入,以达到减少计算量.
2.4.2评估方法
首先让我们找出那些预测正确的标签。tf.argmax 是一个非常有用的函数,它能给出某个tensor对象在某一维上的其数据最大值所在的索引值。由于标签向量是由0,1组成,因此最大值1所在的索引位置就是类别标签,比如tf.argmax(y,1)返回的是模型对于任一输入x预测到的标签值,而 tf.argmax(y_,1) 代表正确的标签,我们可以用 tf.equal 来检测我们的预测是否真实标签匹配(索引位置一样表示匹配)。
correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(y_,1))
这行代码会给我们一组布尔值。为了确定正确预测项的比例,我们可以把布尔值转换成浮点数,然后取平均值。例如,[True, False, True, True] 会变成 [1,0,1,1] ,取平均值后得到 0.75.
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
2.4.3运行代码
确保main.py与input_data.py在同一个文件夹下,建议创建一个空文件夹,然后将下载的代码都放在里面.
在终端运行乳腺癌代码:
python main.py
最终的执行效果如下:
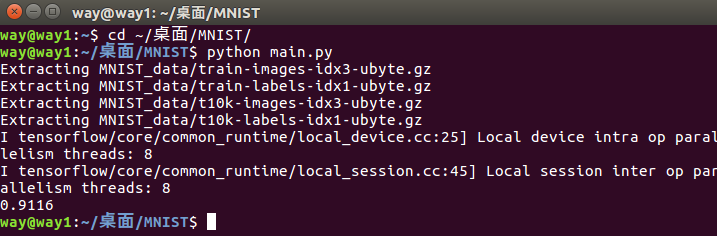
最后的测试正确率在91%左右,其实这个结果并不好,好的算法能达到99%以上.softmax回归(softmax regression)不会去利用结构的信息.也就是说,图有复杂的结构信息,图的空间位置是如何的并不会被利用,所以这个简单的入门教程最后的结果只有90出头的准确率.
2.5 TensorFlow可视化操作----TensorBorad
我们直接运行fully_connected_feed.py
python fully_connected_feed.py
运行好后,会有一系列的日志文件产生:

因为fully_connected_feed.py的代码写法部分内容还停留在0.x的版本,所以我们先安装的0.9版本为了顺利成功运行这个测试代码.但是0.9的安装TensorBoard有问题无法显示内容,所以这里我们要先升级一下我们的TensorFlow版本到1.4,升级后不影响前面MNIST的实验运行.升级办法:
sudo pip install --upgrade tensorflow
升级后,我们就可以使用可视化工具TensorBoard来可视化刚刚那些日志文件啦.执行如下命令:
tensorboard --logdir=/home/way/桌面/MNIST
成功开启的样子如下图:

这里的MNIST文件夹就是我前面说的让读者自行创建用来存放代码的文件夹.
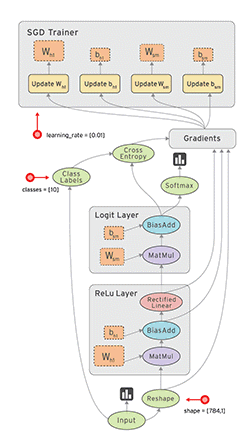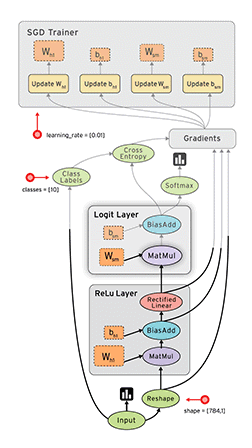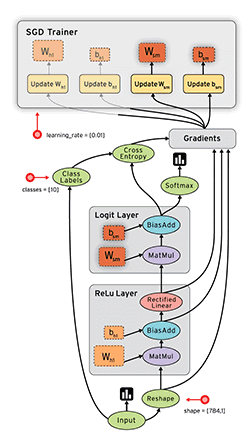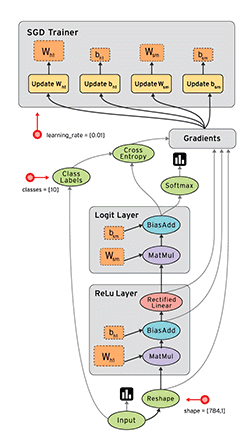
然后我们就可以打开浏览器访问,http://localhost:6006 具体效果如下:

这个图可以部分节点可以展开如下:
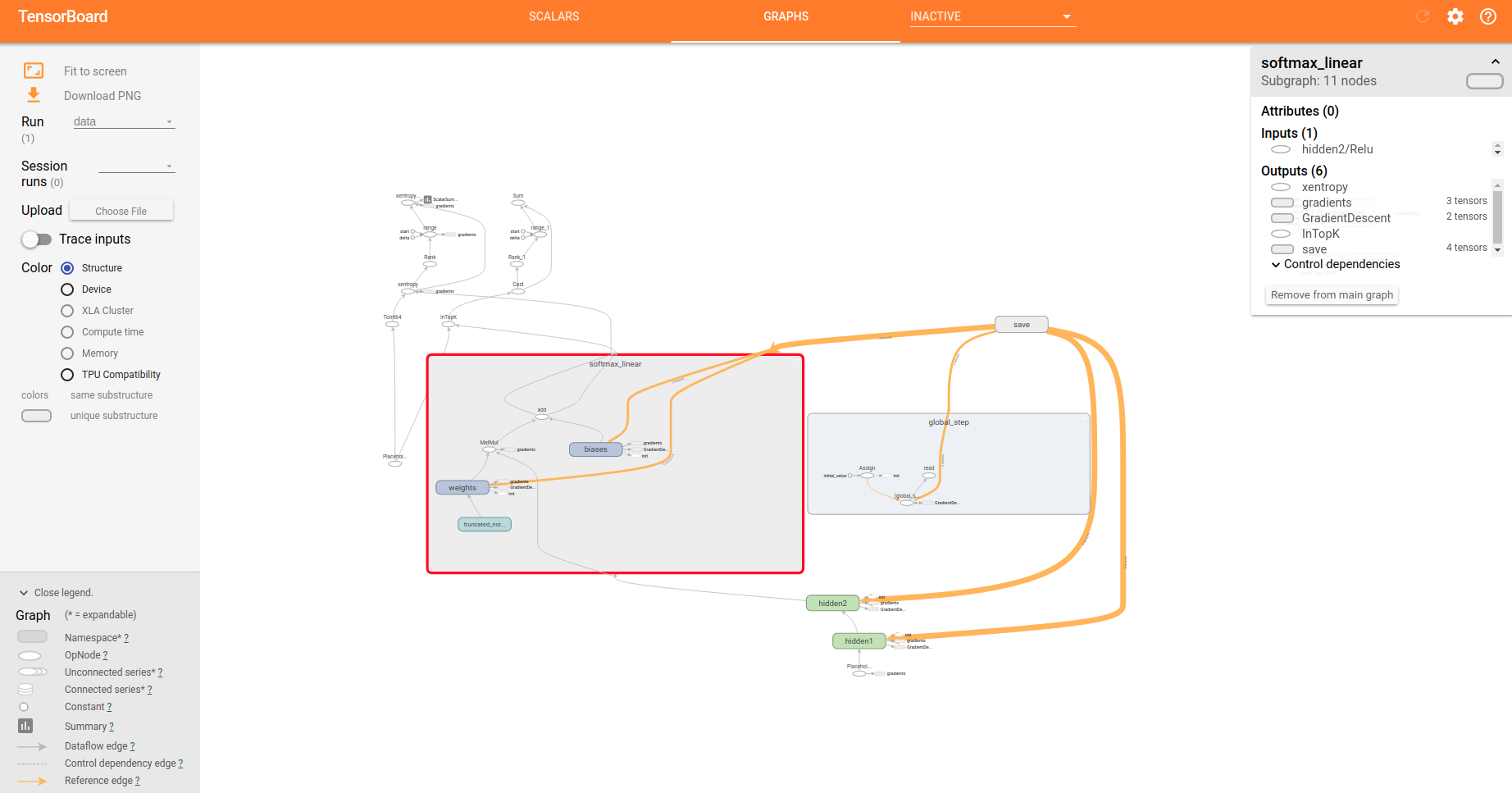
至此,TensorFlow的初级入门教程完成.