
【版权声明】博客内容由厦门大学数据库实验室拥有版权,未经允许,请勿转载!
返回Spark教程首页
推荐纸质教材:林子雨、郑海山、赖永炫编著《Spark编程基础(Python版)》
Word2Vec 是一种著名的 词嵌入(Word Embedding) 方法,它可以计算每个单词在其给定语料库环境下的 分布式词向量(Distributed Representation,亦直接被称为词向量)。词向量表示可以在一定程度上刻画每个单词的语义。
如果词的语义相近,它们的词向量在向量空间中也相互接近,这使得词语的向量化建模更加精确,可以改善现有方法并提高鲁棒性。词向量已被证明在许多自然语言处理问题,如:机器翻译,标注问题,实体识别等问题中具有非常重要的作用。
Word2vec是一个Estimator,它采用一系列代表文档的词语来训练word2vecmodel。该模型将每个词语映射到一个固定大小的向量。word2vecmodel使用文档中每个词语的平均数来将文档转换为向量,然后这个向量可以作为预测的特征,来计算文档相似度计算等等。
Word2Vec具有两种模型,其一是 CBOW ,其思想是通过每个词的上下文窗口词词向量来预测中心词的词向量。其二是 Skip-gram,其思想是通过每个中心词来预测其上下文窗口词,并根据预测结果来修正中心词的词向量。两种方法示意图如下图所示:
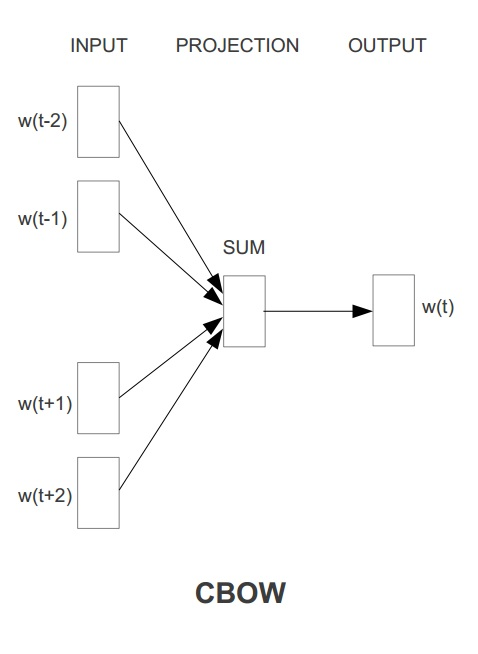
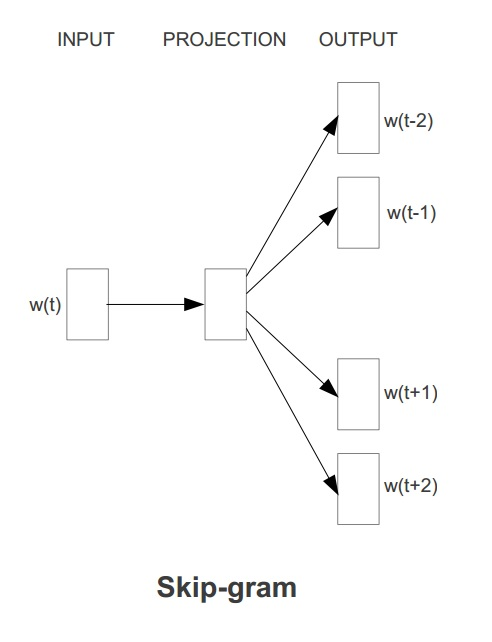
在ml库中,Word2vec 的实现使用的是skip-gram模型。Skip-gram的训练目标是学习词表征向量分布,其优化目标是在给定中心词的词向量的情况下,最大化以下似然函数:
![\[\frac{1}{T}\sum_{t=1}^{T}\sum_{j=-k}^{j=k}log{p(w_{t+j}|w_t)}\]](https://dblab.xmu.edu.cn/blog/wp-content/ql-cache/quicklatex.com-9a8cb93eb8c1f98ebd5c1ae98b8b3390_l3.png "Rendered by QuickLaTeX.com")
其中,
![\[w_1\]](https://dblab.xmu.edu.cn/blog/wp-content/ql-cache/quicklatex.com-5e78e8579d9fa0022c55962e134f45e6_l3.png "Rendered by QuickLaTeX.com")
....
![\[w_t\]](https://dblab.xmu.edu.cn/blog/wp-content/ql-cache/quicklatex.com-6b54876f1e7550937ef9a53c480af608_l3.png "Rendered by QuickLaTeX.com")
是一系列词序列,这里
代表中心词,而
![\[w_{t+j} (j \in [-k,k])\]](https://dblab.xmu.edu.cn/blog/wp-content/ql-cache/quicklatex.com-80691dfb725e0b894cddb2917a97df5b_l3.png "Rendered by QuickLaTeX.com")
是上下文窗口中的词。
这里,每一个上下文窗口词
![\[w_i\]](https://dblab.xmu.edu.cn/blog/wp-content/ql-cache/quicklatex.com-1a47f13ac9a37fcb6911a1b8e17cbb35_l3.png "Rendered by QuickLaTeX.com")
在给定中心词
![\[w_j\]](https://dblab.xmu.edu.cn/blog/wp-content/ql-cache/quicklatex.com-335ae0bbd40ceff23dcad3af832ad2cb_l3.png "Rendered by QuickLaTeX.com")
下的条件概率由类似 Softmax 函数(相当于Sigmoid函数的高维扩展版)的形式进行计算,如下式所示,其中
![\[u_w\]](https://dblab.xmu.edu.cn/blog/wp-content/ql-cache/quicklatex.com-09185e87efdf6ff76aa56624de9bd1cc_l3.png "Rendered by QuickLaTeX.com")
和
![\[v_w\]](https://dblab.xmu.edu.cn/blog/wp-content/ql-cache/quicklatex.com-601e7e796fd3f30691b38caa912f5998_l3.png "Rendered by QuickLaTeX.com")
分别代表当前词的词向量以及当前上下文的词向量表示:
![\[p(w_i|w_j) = \frac{exp(u_{w_i}^{T}v_{w_j})}{\sum_{l=1}^{V}{exp(u_l^Tv_{w_j})}}\]](https://dblab.xmu.edu.cn/blog/wp-content/ql-cache/quicklatex.com-629a40c8811841ca04b8318081b0fee0_l3.png "Rendered by QuickLaTeX.com")
因为Skip-gram模型使用的softmax计算较为复杂,所以,ml与其他经典的Word2Vec实现采用了相同的策略,使用Huffman树来进行 层次Softmax(Hierachical Softmax) 方法来进行优化,使得
![\[\log{p(w_i|w_j)}\]](https://dblab.xmu.edu.cn/blog/wp-content/ql-cache/quicklatex.com-97fe92ae497854f3fff0314b8baa30ab_l3.png "Rendered by QuickLaTeX.com")
计算的复杂度从
![\[O(V)\]](https://dblab.xmu.edu.cn/blog/wp-content/ql-cache/quicklatex.com-ec960b1885f33c255f8efabad9bbfa15_l3.png "Rendered by QuickLaTeX.com")
下降到
![\[O(log(V))\]](https://dblab.xmu.edu.cn/blog/wp-content/ql-cache/quicklatex.com-e8eb0b8c522cf861ec07c1b15ff6e105_l3.png "Rendered by QuickLaTeX.com")
。
在下面的代码段中,我们首先用一组文档,其中一个词语序列代表一个文档。对于每一个文档,我们将其转换为一个特征向量。此特征向量可以被传递到一个学习算法。
下面介绍ML库中Word2Vec类的使用。
我们默认名为spark的SparkSession已经创建。
在下面的代码段中,我们首先用一组文档,其中一个词语序列代表一个文档。对于每一个文档,我们将其转换为一个特征向量。此特征向量可以被传递到一个学习算法。
首先,导入Word2Vec所需要的包,并创建三个词语序列,每个代表一个文档:
from pyspark.ml.feature import Word2Vec
documentDF = spark.createDataFrame([
("Hi I heard about Spark".split(" "), ),
("I wish Java could use case classes".split(" "), ),
("Logistic regression models are neat".split(" "), )
], ["text"])
新建一个Word2Vec,显然,它是一个Estimator,设置相应的超参数,这里设置特征向量的维度为3,Word2Vec模型还有其他可设置的超参数,具体的超参数描述可以参见这里。
word2Vec = Word2Vec(vectorSize=3, minCount=0, inputCol="text", outputCol="result")
读入训练数据,用fit()方法生成一个Word2VecModel。
model = word2Vec.fit(documentDF)
利用Word2VecModel把文档转变成特征向量。
result = model.transform(documentDF)
for row in result.collect():
text, vector = row
print("Text: [%s] => \nVector: %s\n" % (", ".join(text), str(vector)))
Text: [Hi, I, heard, about, Spark] =>
Vector: [0.0127797678113,-0.0934097565711,-0.108308439702]
Text: [I, wish, Java, could, use, case, classes] =>
Vector: [0.0761276933564,0.0345174372196,-0.0429060061329]
Text: [Logistic, regression, models, are, neat] =>
Vector: [-0.0675941422582,0.0452983468771,0.0530217912048]
可以看到,文档被转变为了一个3维的特征向量,这些特征向量就可以被应用到相关的机器学习方法中。