案例介绍
平均心率检测案例。本案例以实验室之前发布的另一篇博客文章《Spark+Kafka构建实时分析Dashboard案例介绍》为基础,涉及模拟数据生成,数据预处理、消息队列发送和接收消息、数据实时处理、数据实时推送和实时展示等数据处理全流程,所涉及的各种典型操作涵盖Linux、Spark、Kafka、JAVA、MySQL、Ajax、Html、Css、Js、Maven等系统和软件的安装和使用方法。通过本案例,将有助于综合运用大数据课程知识以及各种工具软件,实现数据全流程操作。同时在此感谢张少坤、吴维奇和喻小丽等三位同学在创作本案例中的贡献。
实验环境准备
任务清单
- JDK安装
- Hadoop安装
- Maven安装
- Spark安装
- scala安装
- Kafka安装
- MySQL安装
### 实验系统和软件要求
Ubuntu: 16.04
Java : 1.8及以上版本
Scala: 2.11.8
Spark: 2.1.0
kafka: 0.10.1.0
Maven: 3.5.0
MySQL: 5.7.18
系统和软件的安装
JDK安装和Hadoop安装
请参照本教程Hadoop安装教程_单机/伪分布式配置_Hadoop2.6.0/Ubuntu14.04,(ps:请将hadoop改为实验要求的版本号,java的版本号改为8)
Maven安装,Spark安装,scala安装
请参照本教程Spark2.1.0入门:Spark的安装和使用,本套教程涵盖了三种软件的安装
#### Kafka安装
请参照本教程Kafka的安装和简单实例测试
MySQL安装
构建工程架构
spark-homework该链接为案例的代码,下载后输入以下命令。如果出现无法链接到该网页,可以在导航栏里输入pan.baidu.com/s/1ciylS6域名。
cd ~/下载
sudo mkdir -p /usr/local/spark/sparkcode
sudo tar -zxvf spark-homework.tar.gz -C /usr/local/spark/sparkcode
cd /usr/local/spark/sparkcode
chown hadoop:hadoop spark-homework
sudo chmod 777 ./spark-homework
我们将工程目录打包至/usr/local/spark/sparkcode下,方便操作,以下是工程目录:
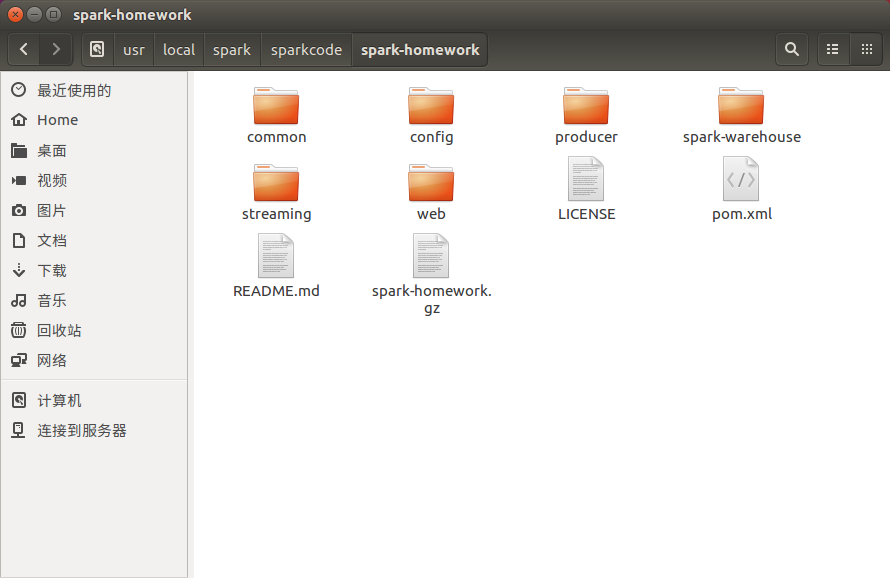
1. common目录存放的是整个项目所公有的类。其中程序文件夹中包含beans, config, db和utils。Beans中存放实体类,config中存放相关配置的类,db中配置数据库的连接等,utils中存放产生Json的工具类等。
2. config目录存放的是整个项目的配置参数,比如kafka生产者的地址和端口号、数据库的配置,如账户名,密码等。Web浏览器访问的地址和端口号等。
3. producer目录存放的是Kafka生产者相关内容。
4. streaming目录存放的是对kafka数据操作并写入数据库的相关文件;
5. web目录存放的含有对http响应的相关处理和资源文件。如js,css,html文件。
注:代码解释只是部分主要功能代码。
数据相关
本案例采用的数据集是由应用程序producer随机产生的。该数据集表示的正常人的心跳速率。下面列出产生的数据格式定义:
1. name | 姓名
2. rate | 心跳率
3. dt | 产生数据的时间
这个案例实时检测平均心率,因此针对每条记录,我们只需要获取name和rate即可,然后发送给Kafka,接下来Spark Streaming再接收进行处理,将其写入MySQL数据库。Web通过间隔若干时间查询某个时间段内的心跳,并对其进行可视化。
数据预处理
本案例通过producer产生数据,并将产生的数据发给kafka,接着可以写如下的Java代码,代码文件名为Run.java,本段代码在/usr/local/spark/sparkcode/spark-homework/producer/src/main/java/com/test目录下,读者可以根据后面的步骤直接运行,不需要拷贝到编译器下:
package com.test;
import com.test.beans.RecordBean;
import com.test.config.ConfigurationFactory;
import com.test.config.objects.Config;
import com.test.producer.Producer;
import com.test.utils.JsonUtils;
import org.apache.log4j.Logger;
import java.util.Random;
public class Run {
private static final Logger LOGGER = Logger.getLogger(Run.class);
private static final Random RANDOM = new Random();
private static final Config CONFIG = ConfigurationFactory.load();
public static void main(String[] args) {
final Producer producer = new Producer();
// catches ctrl+c action
Runtime.getRuntime().addShutdownHook(new Thread(() -> {
LOGGER.info("Generator application stopping ...");
producer.close();
}));
// sleep time as milliseconds for each step
int sleep = RANDOM.nextInt(CONFIG.getGenerator().getRandomRange()) + 10;
RecordBean record;
while (true) {
try {
record = generate();
producer.produce(record.getType().name(), JsonUtils.serialize(record));
Thread.sleep(sleep);
} catch (Throwable t) {
LOGGER.error(t.getMessage(), t);
}
}
}
private static RecordBean generate() {
RecordBean data = new RecordBean();
data.setType(RecordBean.Types.fromNumeric(RANDOM.nextInt(3)));
data.setValue((RANDOM.nextFloat() * 140)+60);
return data;
}
}
上述代码很简单,首先通过随机产生RecordBean实体,然后通过Json工具进行序列化,接着每隔sleep秒发送给kafka。
Streaming操作Kafka
通过streaming操作kafka获取数据,并将数据写入MySQL数据库,代码为App.scala。ps:该代码位于/usr/local/spark/sparkcode/spark-homework/streaming/src/main/scala/com/test下。
package com.test
import java.io.IOException
import java.sql.Timestamp
import java.util.Properties
import com.test.beans.RecordBean
import com.test.config.ConfigurationFactory
import com.test.utils.JsonUtils
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.log4j.Logger
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.types._
import org.apache.spark.sql.{Row, SQLContext, SaveMode, SparkSession}
import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe
import org.apache.spark.streaming.kafka010.KafkaUtils
import org.apache.spark.streaming.kafka010.LocationStrategies.PreferBrokers
import org.apache.spark.streaming.{Seconds, StreamingContext}
object App {
private[this] lazy val logger = Logger.getLogger(getClass)
private[this] val config = ConfigurationFactory.load()
def jsonDecode(text: String): RecordBean = {
try {
JsonUtils.deserialize(text, classOf[RecordBean])
} catch {
case e: IOException =>
logger.error(e.getMessage, e)
null
}
}
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder
.appName("spark-kafka-streaming-example")
.master("local[*]")
.getOrCreate
val streaming = new StreamingContext(spark.sparkContext, Seconds(config.getStreaming.getWindow))
val servers = config.getProducer.getHosts.toArray.mkString(",")
val params = Map[String, Object](
"bootstrap.servers" -> servers,
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"auto.offset.reset" -> "latest",
"group.id" -> "dashboard",
"enable.auto.commit" -> (false: java.lang.Boolean)
)
val topics = Array(config.getProducer.getTopic)
val stream = KafkaUtils.createDirectStream[String, String](
streaming, PreferBrokers, Subscribe[String, String](topics, params))
val schema = StructType(
StructField("name", StringType) ::
StructField("rate", FloatType) ::
StructField("dt", TimestampType) :: Nil
)
val host = config.getStreaming.getDb.getHost
val db = config.getStreaming.getDb.getDb
val url = s"jdbc:mysql://$host/$db"
val table = config.getStreaming.getDb.getTable
val props = new Properties
props.setProperty("driver", "com.mysql.jdbc.Driver")
props.setProperty("user", config.getStreaming.getDb.getUser)
props.setProperty("password", config.getStreaming.getDb.getPass)
type Record = ConsumerRecord[String, String]
stream.foreachRDD((rdd: RDD[Record]) => {
// convert string to PoJo and generate rows as tuple group
val pairs = rdd
.map(row => (row.timestamp(), jsonDecode(row.value())))
.map(row => (row._2.getType.name(), (1, row._2.getValue, row._1)))
val flatten = pairs
.reduceByKey((x, y) => (x._1 + y._1, x._2 + y._2, (y._3 + x._3) / 2))
.map(f => Row.fromSeq(Seq(f._1, f._2._2 / f._2._1, new Timestamp(f._2._3))))
val sql = new SQLContext(flatten.sparkContext)
sql.createDataFrame(flatten, schema)
.repartition(1)
.write
.mode(SaveMode.Append)
.jdbc(url, table, props)
})
// create streaming context and submit streaming jobs
streaming.start()
// wait to killing signals etc.
streaming.awaitTermination()
}
}
编程实现
通过streaming操作kafka获取数据后,将数据写入MySQL数据库。我们可以使用如下代码创建数据库和表。
service mysql start
mysql -u root -p
create database if not exits dashboash_test;
use dashboash_test;
create TABLE IF NOT EXISTS events(
name VARCHAR(24) NOT NULL DEFAULT ' ',
rate FLOAT DEFAULT NULL,
dt DATETIME NOT NULL,
PRIMARY KEY (name,dt)
)
ENGINE=InnoDB DEFAULT CHARSET=utf8=utf8_bin;
再次进入/usr/local/spark/sparkcode/spark-homework/config目录下,对common.conf文件的user和pass选项进行修改。
cd /usr/local/spark/sparkcode/spark-homework/config
sudo vim ./common.conf
编译运行Spark项目
输入以下代码
cd spark-homework
sudo /usr/local/maven/bin/mvn package -DskipTests
如果如下图所示,则说明成功。

开启kafka:
cd /usr/local/kafka
bin/zookeeper-server-start.sh config/zookeeper.properties & bin/kafka-server-start.sh config/server.properties
出现以下图片则运行成功

开启spark streaming 服务并且它会从kafka主题中处理数据到MySQL。重新开启一个终端,前面的终端千万不要关闭。
cd /usr/local/spark/sparkcode/spark-homework
java -Dconfig=./config/common.conf -jar streaming/target/spark-streaming-0.1.jar
开启kafka producer,并且它会将事件写入kafka主题中。重新开启一个终端,前面的终端千万不要关闭。
cd /usr/local/spark/sparkcode/spark-homework/
java -Dconfig=./config/common.conf -jar producer/target/kafka-producer-0.1.jar
成功后如下图所示:
开启web服务器,如此可以观察dashboard。重新开启一个终端,前面的终端千万不要关闭。输入以下代码
cd /usr/local/spark/sparkcode/spark-homework
java -Dconfig=./config/common.conf -jar web/target/web-0.1.jar
开启成功后如下图所示:

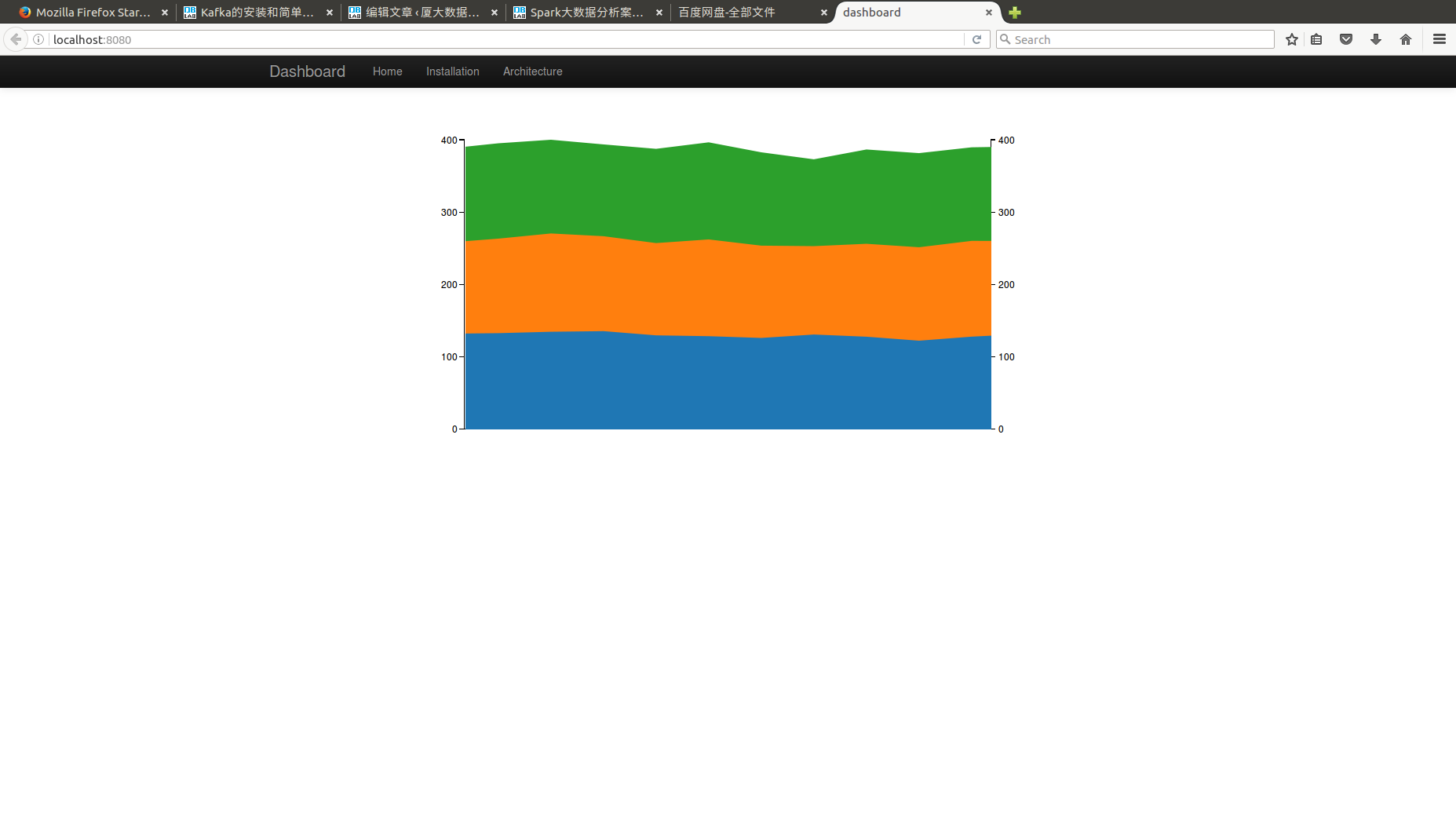
最后在浏览器中输入http://localhost:8080/进行浏览结果。三种颜色分别代表三个人,他们在不同时刻的平均心率。