
本篇文章将利用Spark+Kafka+flask等,来为大家展示一下基本的数据处理操作。本文以之前实验室博客文章《Spark+Kafka构建实时分析Dashboard案例》为基础。强烈建议先学习完该案例再学习这个。
环境搭建请参考《Spark+Kafka构建实时分析Dashboard案例第一部分》
工程结构
首先我们来看一下整体的工程结构,方便大家后续参考。
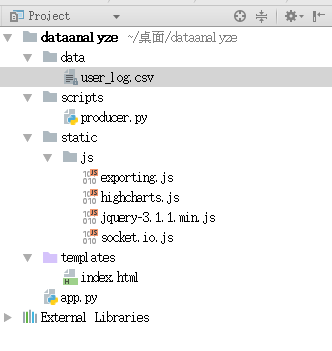
编写producer
在环境搭建好之后,我们需要编写python代码,用来操作生产,保持不间断的发送数据。
创建producer.py并复制下面的代码。
# coding: utf-8
import csv
import time
from kafka import KafkaProducer
# 实例化一个KafkaProducer示例,用于向Kafka投递消息
producer = KafkaProducer(bootstrap_servers='localhost:9092')
# 打开数据文件
csvfile = open("../data/user_log.csv", "r")
# 生成一个可用于读取csv文件的reader
reader = csv.reader(csvfile)
province = []
for line in reader:
if line[10] == 'province':
continue # 去除第一行表头
if line[10] not in province:
province.append(line[10])
if len(province) == 34:
break
province_number = {}
number_province = {}
for u,v in zip(province,range(1,35)):
province_number[u] = v
number_province[v] = u
list_change = ['天津市','北京市','上海市','重庆市']
list_change_to = ['天津','北京','上海','重庆']
for i,j in zip(list_change,list_change_to):
index = province_number[i]
number_province[index] = j
for line in reader:
province1= line[9]
if province1 == 'province':
continue # 去除第一行表头
time.sleep(0.01) # 每隔0.1秒发送一行数据
#发送数据,topic为'province'
producer.send('province', str(province_number[line[10]]).encode('utf8'))
搭建spark处理过程
在这一部分,我们就要开始处理被producer生产并推送出来的在消息队列的消息。
在这一部分我们可以完全参考《Spark+Kafka构建实时分析Dashboard案例第三部分》
搭建服务器
接下来我们要搭建服务器,创建app.py文件,并复制下面的代码
# coding=utf-8
import json
from flask import Flask, render_template
from flask_socketio import SocketIO
from kafka import KafkaConsumer
import pandas as pd
import numpy as np
import csv
import sys
app = Flask(__name__)
app.config['SECRET_KEY'] = 'secret!'
socketio = SocketIO(app)
thread = None
csvfile = open(sys.path[0]+'/data/user_log.csv', "r")#当前路径名+后续路径
reader = csv.reader(csvfile)
province = []
for line in reader:
if line[10] == 'province':
continue
if line[10] not in province:
province.append(line[10])
if len(province) == 34:
break
province_number = {}
number_province = {}
for u,v in zip(province,range(1,35)):
province_number[u] = v
number_province[v] = u
list_change = ['天津市','北京市','上海市','重庆市']
list_change_to = ['天津','北京','上海','重庆']
for i,j in zip(list_change,list_change_to):
index = province_number[i]
number_province[index] = j
number_total = []
for number,name in number_province.items():
new = {}
new['name'] = name
new['value'] = 0
number_total.append(new)
df = pd.DataFrame(number_total)
df = df.set_index('name')
zero = df.copy()
# 实例化一个consumer,接收topic为result的消息
consumer = KafkaConsumer('result')
# 一个后台线程,持续接收Kafka消息,并发送给客户端浏览器
def background_thread():
for msg in consumer:
k = json.loads((msg.value).decode('utf8'))
result = []
for kk in k:
new = {}
for kkk, kkkk in kk.items():
new['name'] = number_province[int(kkk)]
new['value'] = kkkk
result.append(new)
pd_temp = pd.DataFrame(result)
pd_temp = pd_temp.set_index('name')
df_temp = pd.merge(pd_temp, df, 'outer', left_index=True, right_index=True)
df_temp.replace(np.NaN, 0)
df['value'] = df_temp.value_x + df_temp.value_y
df_temp2 = pd.merge(pd_temp,zero,'outer',left_index=True,right_index=True)
df_temp2.replace(np.NaN, 0)
df_temp2['value'] = df_temp2.value_x + df_temp2.value_y
result1 = []
result2 = []
for i, j in zip(list(df_temp2.index), list(df_temp2['value'])):
new = {}
new['name'] = i
new['y'] = int(j)
result1.append(new)
for i, j in zip(list(df.index), list(df['value'])):
new = {}
new['name'] = i
new['value'] = int(j)
result2.append(new)
print(result1)
socketio.emit('test_message', {'data':result2,'data2':result1})
# 客户端发送connect事件时的处理函数
@socketio.on('test_connect')
def connect(message):
print(message)
global thread
if thread is None:
# 单独开启一个线程给客户端发送数据
thread = socketio.start_background_task(target=background_thread)
socketio.emit('connected', {'data': 'Connected'})
# 通过访问http://127.0.0.1:5000/访问
@app.route("/")
def handle_mes():
return render_template("index.html")
# main函数
if __name__ == '__main__':
socketio.run(app, debug=True)
这个的作用就是读取kafka里的经过处理的消息,然后推送给web端。
web端展示
这里我直接提供web文件下载。index.html
右键下载。
首张图片里展示的工程结构,里面的js文件大家可以通过网上搜索下载。
运行步骤
一切文件准备就绪
开启kafka
可以参考文章提到的实验指南。
cd /usr/local/kafka
bin/zookeeper-server-start.sh config/zookeeper.properties &
bin/kafka-server-start.sh config/server.properties
开启spark处理程序
这里我们要进行一点点修改。同样是使用之前的案例文件,但是修改startup .sh文件中的topic:sex,改为province
/usr/local/spark/bin/spark-submit --driver-class-path /usr/local/spark/jars/*:/usr/local/spark/jars/kafka/* --class "org.apache.spark.examples.streaming.KafkaWordCount" /usr/local/spark/mycode/kafka/target/scala-2.11/simple-project_2.11-1.0.jar 127.0.0.1:2181 1 sex 1
/usr/local/spark/bin/spark-submit --driver-class-path /usr/local/spark/jars/*:/usr/local/spark/jars/kafka/* --class "org.apache.spark.examples.streaming.KafkaWordCount" /usr/local/spark/mycode/kafka/target/scala-2.11/simple-project_2.11-1.0.jar 127.0.0.1:2181 1 province 1
改好后,就可以执行相关命令开启程序
cd /usr/local/spark/mycode/kafka/
sh ./startuop.sh
运行producer.py
运行app.py
访问web端
打开浏览器,访问:http://127.0.0.1:5000/
可以看到如下结果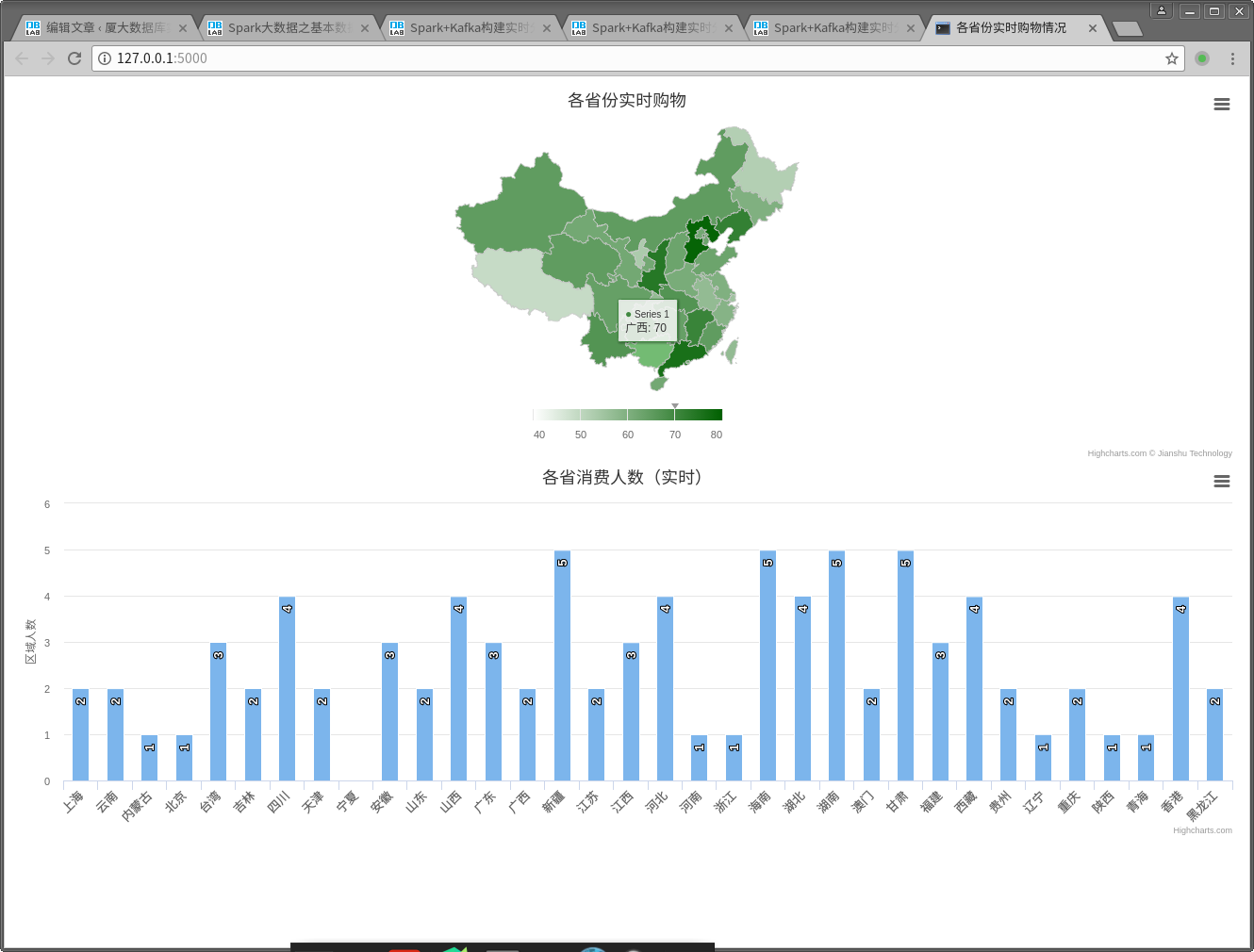
到此为止,实验成功完成!