
【版权声明】博客内容由厦门大学数据库实验室拥有版权,未经允许,请勿转载!
返回Spark教程首页
GraphX是Spark用来图和分布式图计算的新组件。GraphX通过引入属性图:顶点和边均有属性的有向多重图,来扩充Spark的RDD.为了支持这种图计算,GraphX 开发了一组基础功能操作。GraphX仍在不断扩充图算法,用来简化图计算的分析任务。
本章节主要介绍GraphX的核心抽象模型---属性图,并通过实例介绍如何构造一个图。
属性图
属性图是GraphX的核心抽象模型,是一个有向多重图,带有每一个顶点(vertex)和边(edge)的用户自定义对象。由于相同顶点之间存在多种关系,属性图支持平行边,这简化了属性图的建模场景。每个顶点用唯一的64位长的标识符作为键。GraphX没有为顶点标识符排序,每条边都有对应的源和目的顶点标识符。
属性图以顶点(VD)类型和边(ED)类型作为参数,这些类型分别是与顶点和边相关的对象。
注意:GraphX优化了顶点类型和边类型。当用原始数据类型表示(像int,double等)表示顶点或边时,GraphX使用特殊数组来存储,降低内存的消耗。
在某些情况下,同样的图中,可能存在不同的类型的顶点。这些可以通过继承来完成。例如:将用户和产品建模成一个二分图,可以用如下的方式:
class VertexProperty()
case class UserProperty(val name: String) extends VertexProperty
case class ProductProperty(val name: String, val price: Double) extends VertexProperty
// The graph might then have the type:
var graph: Graph[VertexProperty, String] = null
和所有RDD一样,属性图是不可改变的、分布式的、容错的。改变图的值或结构只能通过新建一个新的图来实现。原始图中不受影响的部分(例如:不受影响的结构,属性、索引)都可以在新图中重用,这可以减少存储的成本。还可以利用顶点分区的方法还可以对图进行分区。和所有RDD一样,图的每个分区在发生故障的情况会在不同的机器上重新被创建。
逻辑上,属性图对应一对集合(RDDs),这个集合包含每一个顶点和边属性。因此,属性图的类中包含顶点和边的成员变量.
class Graph[VD, ED] {
val vertices: VertexRDD[VD]
val edges: EdgeRDD[ED]
}
VertexRDD[VD]和EdgeRDD[ED]继承于RDD[(VertexId, VD)]和RDD[Edge[ED]],并做了优化和提供额外的图计算功能。
接下来,我们通过一个实例简单介绍如何构建一个属性图。
属性图实例
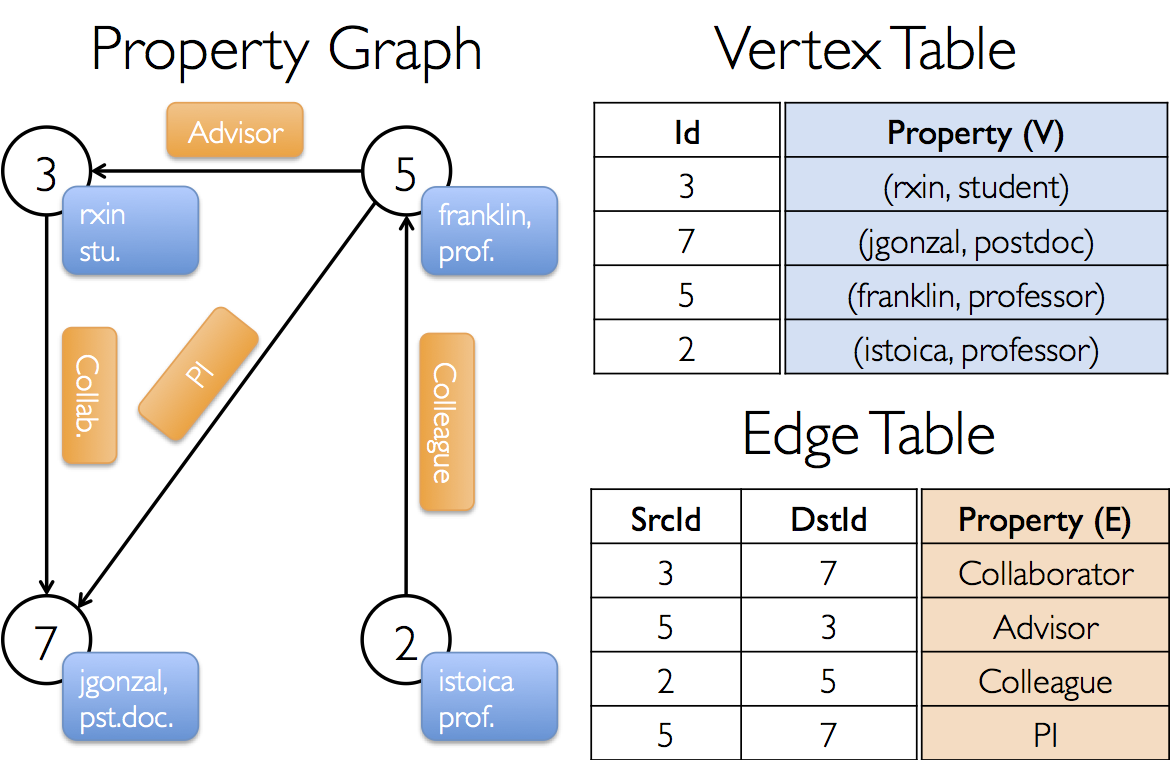
构建一个包含不同作者的属性图,顶点属性包含用户名和职业,边使用字符串描述作者与作者之间的关系。如下图:
下面直接使用一系列RDDs集合来构建图
import org.apache.log4j.{Level,Logger}
import org.apache.spark._
import org.apache.spark.graphx._
import org.apache.spark.rdd.RDD
object SimpleGraphX {
def main(args: Array[String]) {
//屏蔽日志
Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
Logger.getLogger("org.eclipse.jetty.server").setLevel(Level.OFF)
//设置运行环境
val conf = new SparkConf().setAppName("SimpleGraphX").setMaster("local")
val sc = new SparkContext(conf)
//设置users顶点
val users: RDD[(VertexId, (String, String))] =
sc.parallelize(Array((3L, ("rxin", "student")), (7L, ("jgonzal", "postdoc")), (5L, ("franklin", "prof")), (2L, ("istoica", "prof"))))
//设置relationships边
val relationships: RDD[Edge[String]] =
sc.parallelize(Array(Edge(3L, 7L, "collab"),Edge(5L, 3L, "advisor"), Edge(2L, 5L, "colleague"), Edge(5L, 7L, "pi")))
// 定义默认的作者,以防与不存在的作者有relationship边
val defaultUser = ("John Doe", "Missing")
// Build the initial Graph
val graph = Graph(users, relationships, defaultUser)
/***********************************
*展示图的属性
***********************************/
println("属性展示")
println("---------------------------------------------")
println("找到图中属性是student的顶点")
graph.vertices.filter { case (id, (name, occupation)) => occupation=="student"}.collect.foreach {
case (id, (name, occupation)) => println(s"$name is $occupation")
}
println("---------------------------------------------")
println("找到图中边属性是advisor的边")
graph.edges.filter(e => e.attr == "advisor").collect.foreach(e => println(s"${e.srcId} to ${e.dstId} att ${e.attr}"))
println("---------------------------------------------")
println("找出图中最大的出度、入度、度数:")
def max(a: (VertexId, Int), b: (VertexId, Int)): (VertexId, Int) = {
if (a._2 > b._2) a else b
}
println("max of outDegrees:" + graph.outDegrees.reduce(max) + " max of inDegrees:" + graph.inDegrees.reduce(max) + " max of Degrees:" + graph.degrees.reduce(max))
}
}
从Edge Table可以看出,每个边有srcId和dstId对应原顶点和目的顶点标识符,还有一个边属性。同样Vertice Table每个顶点也有各自的属性。
我们可以使用graph.vertices和graph.edges解构出属性图对应的顶点和边,通过graph.outDegrees、graph.inDegrees、graph.degress解构出属性图出度、入度、度数的相关信息。
上述都是Spark GraphX的简单操作,了解更多Spark GraphX的图操作,请访问Spark2.1.0入门:Spark GraphX的图操作