

点击这里观看厦门大学林子雨老师主讲《大数据技术原理与应用》授课视频
网上的 MapReduce WordCount 教程对于如何编译 WordCount.java 几乎是一笔带过... 而有写到的,大多又是 0.20 等旧版本版本的做法,即 javac -classpath /usr/local/hadoop/hadoop-1.0.1/hadoop-core-1.0.1.jar WordCount.java,但较新的 2.X 版本中,已经没有 hadoop-core*.jar 这个文件,因此编辑和打包自己的MapReduce程序与旧版本有所不同。
本文以 Hadoop 2.6.0 单机模式环境下的 WordCount 实例来介绍 2.x 版本中如何编辑自己的 MapReduce 程序。
Hadoop 2.x 版本中的依赖 jar
Hadoop 2.x 版本中 jar 不再集中在一个 hadoop-core*.jar 中,而是分成多个 jar,如使用 Hadoop 2.6.0 运行 WordCount 实例至少需要如下三个 jar:
- $HADOOP_HOME/share/hadoop/common/hadoop-common-2.6.0.jar
- $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-client-core-2.6.0.jar
- $HADOOP_HOME/share/hadoop/common/lib/commons-cli-1.2.jar
实际上,通过命令 hadoop classpath 我们可以得到运行 Hadoop 程序所需的全部 classpath 信息。
编译、打包 Hadoop MapReduce 程序
我们将 Hadoop 的 classhpath 信息添加到 CLASSPATH 变量中,在 ~/.bashrc 中增加如下几行:
export HADOOP_HOME=/usr/local/hadoop
export CLASSPATH=$($HADOOP_HOME/bin/hadoop classpath):$CLASSPATH
别忘了执行 source ~/.bashrc 使变量生效,接着就可以通过 javac 命令编译 WordCount.java 了(使用的是 Hadoop 源码中的 WordCount.java,源码在文本最后面):
javac WordCount.java
编译时会有警告,可以忽略。编译后可以看到生成了几个 .class 文件。
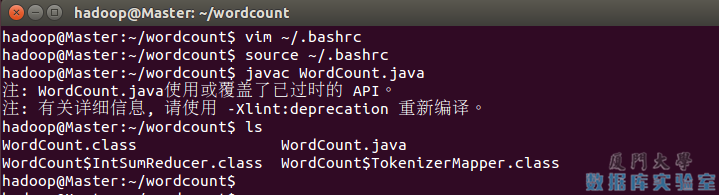
接着把 .class 文件打包成 jar,才能在 Hadoop 中运行:
jar -cvf WordCount.jar ./WordCount*.class
打包完成后,运行试试,创建几个输入文件:
mkdir input
echo "echo of the rainbow" > ./input/file0
echo "the waiting game" > ./input/file1

如果读者Hadoop的环境是单机模式,请跳过此步骤。如果读者的Hadoop环境已经配置成伪分布式,那么读者还需要进行执行下列操作命令:
# 把本地文件上传到伪分布式HDFS上
/usr/local/hadoop/bin/hadoop fs -put ./input input
开始运行。直接运行/usr/local/hadoop/bin/hadoop jar WordCount.jar WordCount input output,可能会出现找不到类的错误:
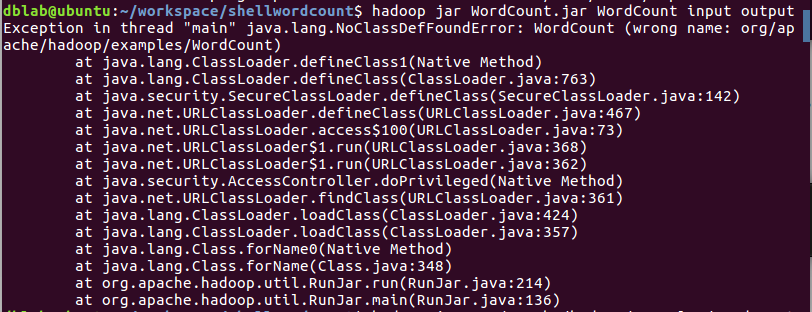
这是因为我们在代码中设置了package包名,这里也要写全,正确的命令如下。
/usr/local/hadoop/bin/hadoop jar WordCount.jar org/apache/hadoop/examples/WordCount input output
正确运行后的结果如下:
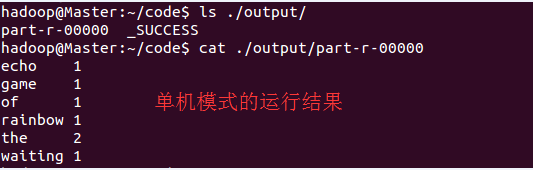
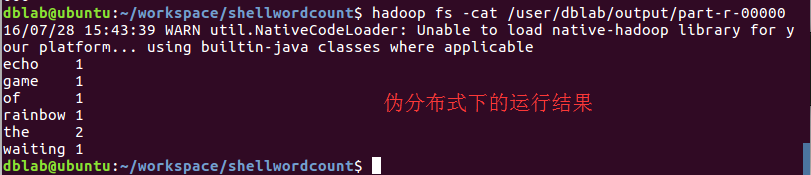
Tips:如果读者已经将Hadoop的bin目录添加到环境变量,那么每一句命令的/usr/local/hadoop/bin/都可以不写。
进阶:使用 Eclipse 编译运行 MapReduce 程序
使用命令行编译运行 MapReduce 程序毕竟有些麻烦,修改一次就得手动编译、打包一次,使用Eclipse编译运行MapReduce程序会更加方便。
WordCount.java 源码
文件位于 hadoop-2.6.0-src\hadoop-mapreduce-project\hadoop-mapreduce-examples\src\main\java\org\apache\hadoop\examples 中:
import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public WordCount() {
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = (new GenericOptionsParser(conf, args)).getRemainingArgs();
if(otherArgs.length < 2) {
System.err.println("Usage: wordcount <in> [<in>...] <out>");
System.exit(2);
}
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(WordCount.TokenizerMapper.class);
job.setCombinerClass(WordCount.IntSumReducer.class);
job.setReducerClass(WordCount.IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
for(int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true)?0:1);
}
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public IntSumReducer() {
}
public void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
int sum = 0;
IntWritable val;
for(Iterator i$ = values.iterator(); i$.hasNext(); sum += val.get()) {
val = (IntWritable)i$.next();
}
this.result.set(sum);
context.write(key, this.result);
}
}
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
private static final IntWritable one = new IntWritable(1);
private Text word = new Text();
public TokenizerMapper() {
}
public void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while(itr.hasMoreTokens()) {
this.word.set(itr.nextToken());
context.write(this.word, one);
}
}
}
}