【版权声明】版权所有,严禁转载,严禁用于商业用途,侵权必究。
作者:厦门大学信息学院2020级研究生 杨志鹏
指导老师:厦门大学数据库实验室 林子雨 博士/副教授
相关教材:林子雨、陶继平编著《Flink编程基础(Scala版)》(官网)
相关案例:基于Scala语言的Flink数据处理分析案例集锦
本实验针对奥运会数据进行分析,使用scala语言进行flink编程来处理数据,最后结果使用python进行可视化
一、实验环境
(1)Windows10
(2)Java:1.8
(3)Scala:2.11.12
(4)Python:3.x
(5)Python包:Matplotlib、Pandas
(6)所需工具:Maven、IntelloJ IDEA、Jupyter Notebook
二、项目创建说明
1.安装maven,在终端输入如下命令创建scala版flink项目
mvn archetype:generate -DarchetypeGroupId=org.apache.flink -DarchetypeArtifactId=flink-quickstart-scala -DarchetypeVersion=1.13.0 -DgroupId=org.apache.flink.quickstart -DartifactId=flink-scala-project -Dversion=0.1 -Dpackage=org.apache.flink.quickstart -DinteractiveMode=false
2.打开IntelliJ IDEA配置项目的环境
(1)添加相关依赖包
打开第1步所创建的pom.xml文件
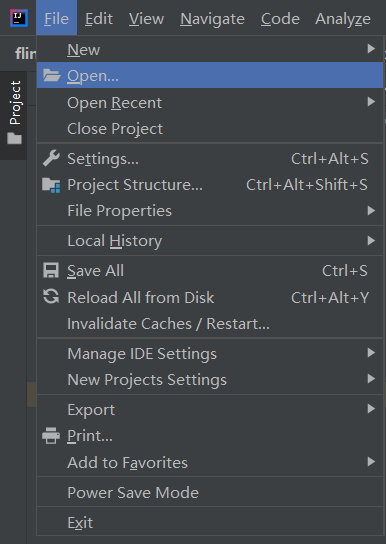
选择open as project,然后在pom,xml中添加如下内容(table API和csv格式相关的依赖包)并更新
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-scala-bridge_2.11</artifactId>
<version>1.13.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_2.11</artifactId>
<version>1.13.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.11</artifactId>
<version>1.13.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-csv</artifactId>
<version>1.13.0</version>
</dependency>
(2)设置好与pom.xml中相对应的java版本和scala版本
点击file,然后点击project structure
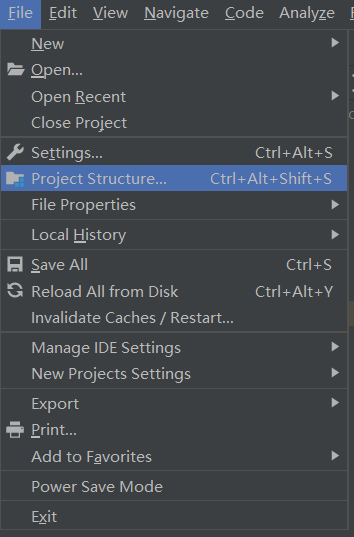
在poject SDK中选择JDK1.8
在module SDK中选择JDK1.8
在SDKs中选择JDK1.8
在global libraries中选择scala-sdk-2.11.12
(3)创建scala文件,并配置运行环境
新建一个名为”Homework”的scala文件,在这个scala文件内编写代码,最后运行代码,注意在运行代码时需要进行下面所示的一些运行配置
在右上角中点击edit configurations
在modify options中勾选include dependencies with “provided” scope并保存,接下来就可以直接运行所写的scala代码了

三、数据集说明
本次作业所使用的数据集为olympic-athletes.csv文件(从百度网盘下载数据集,提取码:ziyu),数据集中包含了2000年到2012年一部分(一共153名)选手的信息。
文件内每行的内容及类型如下:
第1列为运动员名字,格式为String;
第2列为国家,格式为String
第3列为年份,格式为Int
第4列为运动项目,格式为String
第5列为获得的金牌数,格式为Int
第6列为获得的银牌数,格式为Int
第7列为获得的铜牌数,格式为Int
第8列为总共获得的奖牌数,格式为Int
部分数据如下图所示
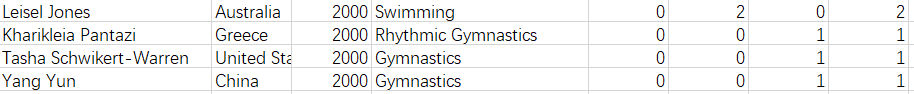
四、步骤概述
首先在IDEA中使用scala利用flink对数据集进行处理,统计每个国家的总人数,每个运动项目的总人数,每个国家所获得的的总奖牌数,并分别输出数据到3个csv文件people_per_country.csv,people_per_Game.csv,total_per_country.csv。然后在jupyter notebook中使用python读取这3个csv文件并进行可视化。
五、代码详解
实验完整工程文件从百度云盘获取(提取码:ziyu),下面分块介绍具体代码作用。
1、scala代码数据处理(位于文件夹内的flink-scala-project\src\main\scala\org\apache\flink\quickstart\Homework.scala中)
导入相关的包
import org.apache.flink.api.common.functions.AggregateFunction
import org.apache.flink.api.scala._
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment}
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.table.api.DataTypes
import org.apache.flink.table.api.bridge.scala.StreamTableEnvironment
import org.apache.flink.table.descriptors.{Csv, FileSystem, Schema}
import org.apache.flink.util.Collector
import java.util.Calendar
在数据处理过程中使用了flink提供的datastream API和tableAPI,因为需要进行批处理但是使用了datastream API,因此需要使用窗口window的概念将流处理转化为批处理(如果不使用window,则每接收到一个数据就需要进行处理并得到一个输出;当使用了window,则可以对这个窗口内的所有数据进行处理后再得到一个输出)。Window可以使用时间窗口和计数窗口,这里采用时间窗口进行数据处理,所用的时间又分为processing时间和event时间,这里采用了event时间进行处理。当使用event时间时,还需要用到watermark的概念。因此创建steam环境和table环境的代码如下(在steam环境中设置event时间,并每1秒发送一个watermark):
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
env.getConfig.setAutoWatermarkInterval(1000L)
val tEnv = StreamTableEnvironment.create(env)
接下来使用table API来读取olympic-athletes.csv文件,并设置每列数据的名称以便于后续进行数据处理,读取文件得到的表数据取名为”my_table”,注意运行代码时文件路径需要进行修改:
val schema = new Schema()
.field("player", DataTypes.STRING())
.field("Country", DataTypes.STRING())
.field("Year", DataTypes.INT())
.field("Game", DataTypes.STRING())
.field("Gold", DataTypes.INT())
.field("Silver", DataTypes.INT())
.field("Bronze", DataTypes.INT())
.field("Total", DataTypes.INT())
tEnv.connect(new FileSystem().path("C:\\Users\\60549\\Desktop\\杨志鹏-31520201153900\\olympic-athletes.csv"))
.withFormat(new Csv().deriveSchema())
.withSchema(schema)
.createTemporaryTable("my_table")
val table = tEnv.from("my_table")
在得到表数据table后,需要将table转换为DataStream类型,然后就可以使用flink提供的datastream API进行数据处理,为了方便处理,首先定义一个case class
case class Athlete(player:String, Country:String, Years:Int, Game:String, Gold:Int, Silver:Int, Bronze:Int, Total:Int)
然后将table数据转换为DataStream类型数据
val athletes = tEnv.toAppendStream[Athlete](table)
上面得到的athletes的类型为DataStream[Athlete],由于后面时间窗口使用的event时间需要数据源提供时间戳,为了方便再建立一个时间戳属性的case class:
case class AthleteWithTime(player:String, Country:String, Years:Int, Game:String, Gold:Int, Silver:Int, Bronze:Int, Total:Int, Time:Long)
接下来是构建一个带有时间戳的数据流:
val athletesWithTime= athletes.map(player=>new AthleteWithTime(player.player, player.Country,player.Years,player.Game,player.Gold,player.Silver,player.Bronze,player.Total,Calendar.getInstance.getTimeInMillis)).assignTimestampsAndWatermarks(new TimeAssigner)
在上面的代码中,最后给带有时间戳的数据流定义了(定义在TimeAssigner里)如何从数据流中提取时间戳,以及watermark的生成方式, TimeAssigner的具体代码如下:
class TimeAssigner
extends BoundedOutOfOrdernessTimestampExtractor[AthleteWithTime](Time.seconds(5)) {
override def extractTimestamp(r: AthleteWithTime): Long = r.Time
}
上面代码中使用了flink提供的BoundedOutOfOrdernessTimestampExtractor,这可以使得乱序的数据和稍微延迟(5秒)的数据得到处理。在得到数据源后,就可以对数据进行处理了,首先统计每个国家的总人数:
val peoplePerCountry = athletesWithTime
.map(player => (player.Country,1))
.keyBy(0)
.timeWindow(Time.seconds(5))
.sum(1)
上面代码中使用了时间窗口的概念,将流处理转为批处理,时间窗口的大小决定了所能处理的批的大小,为了将整个数据集都得到批处理,这里将时间窗口的大小设置得足够大(5秒)。然后是统计每个运动项目的总人数,这里采用reduce函数实现sum的功能(reduce函数的输入为两个相同类型的数据,输出为一个相同类型的数据,因此利用reduce可以实现一些较简单的数据滚动处理比如sum):
val peoplePerGame = athletesWithTime
.map(player => (player.Game,1))
.keyBy(0)
.timeWindow(Time.seconds(5))
.reduce((a,b)=>(a._1, a._2 + b._2))
最后是统计每个国家获得的总奖牌数,这里采用aggregate来实现sum的功能(aggregate函数是reduce的推广,它的输出类型可以和输入类型不相同,因此可以利用aggregate实现比较复杂的数据滚动处理):
val totalPerCountry = athletesWithTime
.map(player => (player.Country, player.Total))
.keyBy(0)
.timeWindow(Time.seconds(5))
.aggregate(new MySum)
上面代码中的MySum首先需要定义一个存放中间处理结果的accumulator,然后再定义由输入数据得到accumulator的方式,最后从最终的accumulator提取出完整的结果,完整定义如下所示(由于只有session时间窗口才需要实现merge函数,而这里使用的窗口是tumbling时间窗口,所以merge函数只要返回null即可):
class MySum
extends AggregateFunction[(String, Int), (String, Int), (String, Int)] {
override def createAccumulator() = {
("", 0)
}
override def add(in: (String, Int), acc: (String, Int)) = {
(in._1, in._2 + acc._2)
}
override def getResult(acc: (String, Int)) = {
(acc._1, acc._2)
}
override def merge(acc1: (String, Int), acc2: (String, Int)) = {
null
}
}
在得到处理完的流数据后,将这些流数据输出到csv格式中去(注意运行代码时文件路径需要进行修改),由于flink是并行处理,所以最后输出到一个csv文件时需要设置并行度为1,这里注意因为在作业文件夹中已经存在这三个csv文件,因此重新运行时需要先删除原来的csv文件,再运行代码得到这三个csv文件:
peoplePerCountry.writeAsCsv("C:\\Users\\60549\\Desktop\\杨志鹏-31520201153900\\people_per_country.csv").setParallelism(1)
peoplePerGame.writeAsCsv("C:\\Users\\60549\\Desktop\\杨志鹏-31520201153900\\people_per_Game.csv").setParallelism(1)
totalPerCountry.writeAsCsv("C:\\Users\\60549\\Desktop\\杨志鹏-31520201153900\\total_per_country.csv").setParallelism(1)
env.execute()
这里将上面所述的完整scala代码进行展示:
import org.apache.flink.api.common.functions.AggregateFunction
import org.apache.flink.api.scala._
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment}
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.table.api.DataTypes
import org.apache.flink.table.api.bridge.scala.StreamTableEnvironment
import org.apache.flink.table.descriptors.{Csv, FileSystem, Schema}
import org.apache.flink.util.Collector
import java.util.Calendar
object Homework {
def main(args: Array[String]) {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
env.getConfig.setAutoWatermarkInterval(1000L)
val tEnv = StreamTableEnvironment.create(env)
val schema = new Schema()
.field("player", DataTypes.STRING())
.field("Country", DataTypes.STRING())
.field("Year", DataTypes.INT())
.field("Game", DataTypes.STRING())
.field("Gold", DataTypes.INT())
.field("Silver", DataTypes.INT())
.field("Bronze", DataTypes.INT())
.field("Total", DataTypes.INT())
tEnv.connect(new FileSystem().path("C:\\Users\\60549\\Desktop\\杨志鹏-31520201153900\\olympic-athletes.csv"))
.withFormat(new Csv().deriveSchema())
.withSchema(schema)
.createTemporaryTable("my_table")
val table = tEnv.from("my_table")
val athletes = tEnv.toAppendStream[Athlete](table)
val athletesWithTime= athletes.map(player=>new AthleteWithTime(player.player, player.Country,player.Years,
player.Game,player.Gold,player.Silver,player.Bronze,player.Total,Calendar.getInstance.getTimeInMillis))
.assignTimestampsAndWatermarks(new TimeAssigner)
val peoplePerCountry = athletesWithTime
.map(player => (player.Country,1))
.keyBy(0)
.timeWindow(Time.seconds(5))
.sum(1)
val peoplePerGame = athletesWithTime
.map(player => (player.Game,1))
.keyBy(0)
.timeWindow(Time.seconds(5))
.reduce((a,b)=>(a._1, a._2 + b._2))
val totalPerCountry = athletesWithTime
.map(player => (player.Country, player.Total))
.keyBy(0)
.timeWindow(Time.seconds(5))
.aggregate(new MySum)
peoplePerCountry.writeAsCsv("C:\\Users\\60549\\Desktop\\杨志鹏-31520201153900\\people_per_country.csv").setParallelism(1)
peoplePerGame.writeAsCsv("C:\\Users\\60549\\Desktop\\杨志鹏-31520201153900\\people_per_Game.csv").setParallelism(1)
totalPerCountry.writeAsCsv("C:\\Users\\60549\\Desktop\\杨志鹏-31520201153900\\total_per_country.csv").setParallelism(1)
env.execute()
}
}
case class Athlete(player:String, Country:String, Years:Int, Game:String, Gold:Int, Silver:Int, Bronze:Int, Total:Int)
case class AthleteWithTime(player:String, Country:String, Years:Int, Game:String, Gold:Int, Silver:Int, Bronze:Int, Total:Int, Time:Long)
class TimeAssigner
extends BoundedOutOfOrdernessTimestampExtractor[AthleteWithTime](Time.seconds(5)) {
override def extractTimestamp(r: AthleteWithTime): Long = r.Time
}
class MySum
extends AggregateFunction[(String, Int), (String, Int), (String, Int)] {
override def createAccumulator() = {
("", 0)
}
override def add(in: (String, Int), acc: (String, Int)) = {
(in._1, in._2 + acc._2)
}
override def getResult(acc: (String, Int)) = {
(acc._1, acc._2)
}
override def merge(acc1: (String, Int), acc2: (String, Int)) = {
null
}
}
2、python代码可视化(位于文件夹的” python代码可视化.ipynb”中)
在处理完数据并得到相应的csv文件后,可以打开jupyter notebook,写入python代码读取相关的csv文件并进行可视化。在终端输入jupyter-lab打开jupyter notebook。
首先导入相关的包,并读取csv文件:
import pandas as pd
import matplotlib.pyplot as plt
#当python文件和csv文件路径不同时要修改运行路径
people_per_country = pd.read_csv("people_per_country.csv", header=None, names=["country", "people"], index_col=0)
people_per_game = pd.read_csv("people_per_game.csv", header=None, names=["game", "people"], index_col=0)
total_per_country = pd.read_csv("total_per_country.csv", header=None, names=["country", "total"], index_col=0)
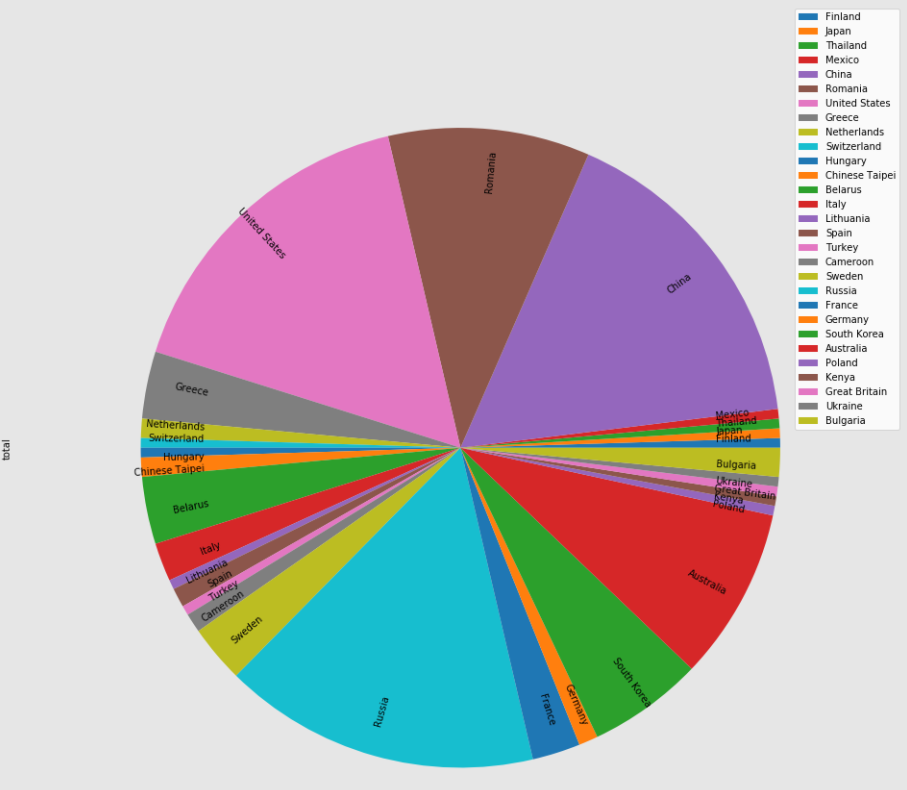
(1)画出每个国家总人数条形图和饼图:
people_per_country.plot.bar()
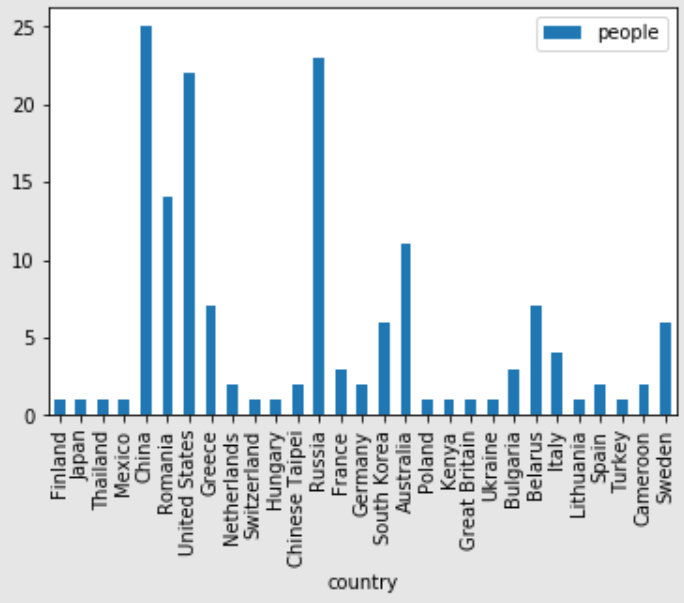
people_per_country.plot.pie(subplots=True, figsize=(15,15),rotatelabels=True,labeldistance=0.8,radius=0.9,fontsize=11)
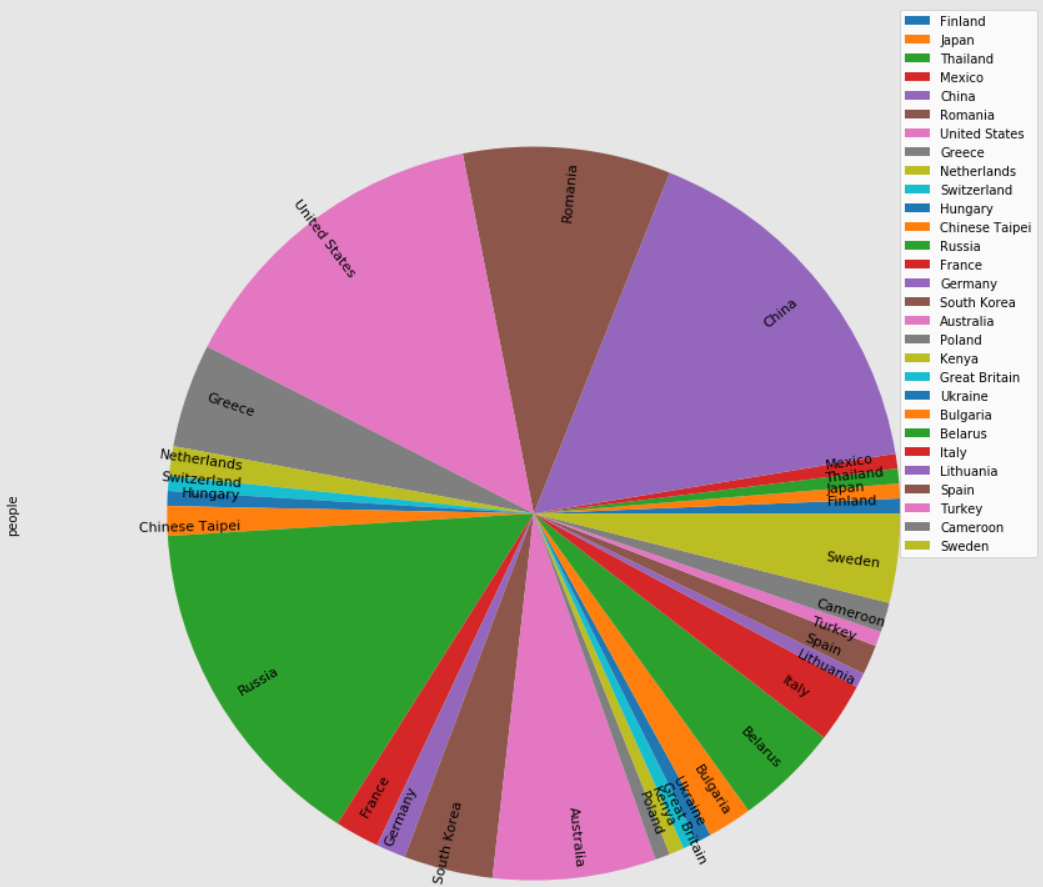
(2)画出每个运动项目参加总人数的条形图和饼图:
people_per_game.plot.bar()
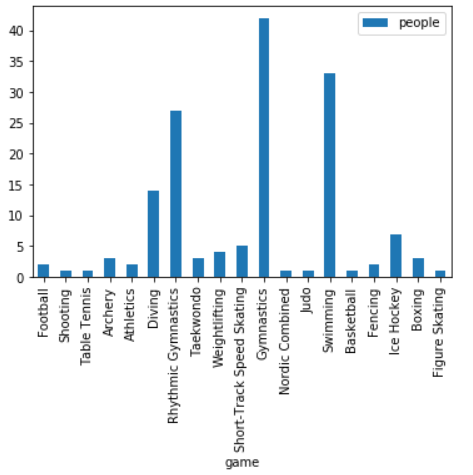
people_per_game.plot.pie(subplots=True, figsize=(15,15),rotatelabels=True,labeldistance=0.8,radius=0.5,fontsize=20)

(3)画出每个国家获得奖牌总数的条形图和饼图:
total_per_country.plot.bar()
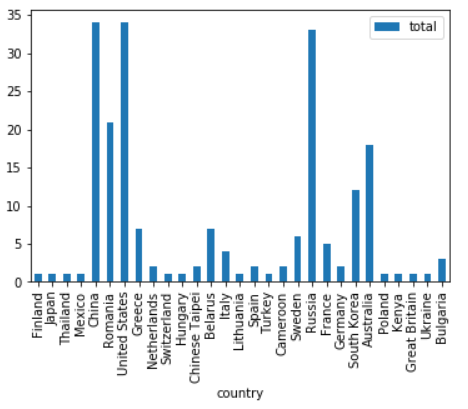
total_per_country.plot.pie(subplots=True, figsize=(17,17),rotatelabels=True,labeldistance=0.8,radius=0.9,fontsize=10)