
先前的文章展示了爬虫分析,并使用pyecharts画图。这篇文章在先前文章的基础上,增加了在线控制模块。总体的做法就是,把爬虫分析功能放在后台,在后台开启一个服务端,接收客户端的命令后,开启爬虫分析,然后将最后的结果展示在客户端。
这里先给出工程截图,后面新建文件的时候就不会再详细说明应该放在哪一个目录下了。
顺带一提,init.py这个文件是用来索引用的,文件内容为空就行,如果没有出现无法import爬虫模块代码的情况,就无需添加这个文件。
接下来文章将分为大致三个部分,第一部分是后台的爬虫分析模块,第二部分是后台的用flask构建服务端模块,以及第三部分是客户端的编写html部分。
注意,这次的工程我使用的是本地的python环境了,在pycharm新建工程的时候是可以选择本地运行环境的。python版本3.6。正常来说,python3的版本都可以使用。只是要注意安装相关的模块。可以使用pycharm的红色感叹号提示来install相关模块。也可以开启终端自行安装。使用本地的环境就可以永久使用了,这就很方便了。需要安装的模块,请参考先前的文章。此外还增加了flask模块,flask_socketio模块。
sudo pip3 install flask
sudo pip3 install flask-socketio
第一步 爬虫分析
该部分与文章开头的链接相差无几。只是少了一个程序总运行程序,因为我把总运行程序部分写到了flask后台服务里了。
首先是要创建爬去网页内容的rent_spider.py。代码如下:
# -*- coding: utf-8 -*-
import requests
from bs4 import BeautifulSoup
import csv
# num表示记录序号
Url_head = "http://fangzi.xmfish.com/web/search_hire.html?h=&hf=&ca=5920"
Url_tail = "&r=&s=&a=&rm=&f=&d=&tp=&l=0&tg=&hw=&o=&ot=0&tst=0&page="
Num = 0
Filename = "./data/rent.csv"
# 把每一页的记录写入文件中
def write_csv(msg_list):
out = open(Filename, 'a', newline='')
csv_write = csv.writer(out,dialect='excel')
for msg in msg_list:
csv_write.writerow(msg)
out.close()
# 访问每一页
def acc_page_msg(page_url):
web_data = requests.get(page_url).content.decode('utf8')
soup = BeautifulSoup(web_data, 'html.parser')
address_list = []
area_list = []
num_address = 0
num_area = 0
msg_list = []
# 得到了地址列表,以及区域列表
for tag in soup.find_all(attrs="list-addr"):
for em in tag:
count = 0
for a in em:
count += 1
if count == 1 and a.string != "[":
address_list.append(a.string)
elif count == 2:
area_list.append(a.string)
num_area += 1
elif count == 4:
if a.string is not None:
address_list[num_address] = address_list[num_address] + "-" + a.string
else:
address_list[num_address] = address_list[num_address] + "-Null"
num_address += 1
# 得到了价格列表
price_list = []
for tag in soup.find_all(attrs="list-price"):
price_list.append(tag.b.string)
# 组合成为一个新的tuple——list并加上序号
for i in range(len(price_list)):
txt = (address_list[i], area_list[i], price_list[i])
msg_list.append(txt)
# 写入csv
write_csv(msg_list)
# 爬所有的页面
def get_pages_urls():
urls = []
# 思明可访问页数134
for i in range(134):
urls.append(Url_head + "1" + Url_tail + str(i+1))
# 湖里可访问页数134
for i in range(134):
urls.append(Url_head + "2" + Url_tail + str(i+1))
# 集美可访问页数27
for i in range(27):
urls.append(Url_head + "3" + Url_tail + str(i+1))
# 同安可访问页数41
for i in range(41):
urls.append(Url_head + "4" + Url_tail + str(i+1))
# 翔安可访问页数76
for i in range(76):
urls.append(Url_head + "5" + Url_tail + str(i+1))
# 海沧可访问页数6
for i in range(6):
urls.append(Url_head + "6" + Url_tail + str(i+1))
return urls
def run():
print("开始爬虫")
out = open(Filename, 'a', newline='')
csv_write = csv.writer(out, dialect='excel')
title = ("address", "area", "price")
csv_write.writerow(title)
out.close()
url_list = get_pages_urls()
for url in url_list:
try:
acc_page_msg(url)
except:
print("格式出错", url)
print("结束爬虫")
该模块的代码不做太多介绍,详细信息可以参考,文章开头的链接。
接着创建rent_analyse.py文件。代码如下:
# -*- coding: utf-8 -*-
from pyspark.sql import SparkSession
from pyspark.sql.types import IntegerType
def spark_analyse(filename):
print("开始spark分析")
# 程序主入口
spark = SparkSession.builder.master("local").appName("rent_analyse").getOrCreate()
df = spark.read.csv(filename, header=True)
# max_list存储各个区的最大值,0海沧,1为湖里,2为集美,3为思明,4为翔安,5为同安;同理的mean_list, 以及min_list,approxQuantile中位数
max_list = [0 for i in range(6)]
mean_list = [1.2 for i in range(6)]
min_list = [0 for i in range(6)]
mid_list = [0 for i in range(6)]
# 类型转换,十分重要,保证了price列作为int用来比较,否则会用str比较, 同时排除掉一些奇怪的价格,比如写字楼的出租超级贵
# 或者有人故意标签1元,其实要面议, 还有排除价格标记为面议的
df = df.filter(df.price != '面议').withColumn("price", df.price.cast(IntegerType()))
df = df.filter(df.price >= 50).filter(df.price <= 40000)
mean_list[0] = df.filter(df.area == "海沧").agg({"price": "mean"}).first()['avg(price)']
mean_list[1] = df.filter(df.area == "湖里").agg({"price": "mean"}).first()['avg(price)']
mean_list[2] = df.filter(df.area == "集美").agg({"price": "mean"}).first()['avg(price)']
mean_list[3] = df.filter(df.area == "思明").agg({"price": "mean"}).first()['avg(price)']
mean_list[4] = df.filter(df.area == "翔安").agg({"price": "mean"}).first()['avg(price)']
mean_list[5] = df.filter(df.area == "同安").agg({"price": "mean"}).first()['avg(price)']
min_list[0] = df.filter(df.area == "海沧").agg({"price": "min"}).first()['min(price)']
min_list[1] = df.filter(df.area == "湖里").agg({"price": "min"}).first()['min(price)']
min_list[2] = df.filter(df.area == "集美").agg({"price": "min"}).first()['min(price)']
min_list[3] = df.filter(df.area == "思明").agg({"price": "min"}).first()['min(price)']
min_list[4] = df.filter(df.area == "翔安").agg({"price": "min"}).first()['min(price)']
min_list[5] = df.filter(df.area == "同安").agg({"price": "min"}).first()['min(price)']
max_list[0] = df.filter(df.area == "海沧").agg({"price": "max"}).first()['max(price)']
max_list[1] = df.filter(df.area == "湖里").agg({"price": "max"}).first()['max(price)']
max_list[2] = df.filter(df.area == "集美").agg({"price": "max"}).first()['max(price)']
max_list[3] = df.filter(df.area == "思明").agg({"price": "max"}).first()['max(price)']
max_list[4] = df.filter(df.area == "翔安").agg({"price": "max"}).first()['max(price)']
max_list[5] = df.filter(df.area == "同安").agg({"price": "max"}).first()['max(price)']
# 返回值是一个list,所以在最后加一个[0],才能取到里面的数值
mid_list[0] = df.filter(df.area == "海沧").approxQuantile("price", [0.5], 0.01)[0]
mid_list[1] = df.filter(df.area == "湖里").approxQuantile("price", [0.5], 0.01)[0]
mid_list[2] = df.filter(df.area == "集美").approxQuantile("price", [0.5], 0.01)[0]
mid_list[3] = df.filter(df.area == "思明").approxQuantile("price", [0.5], 0.01)[0]
mid_list[4] = df.filter(df.area == "翔安").approxQuantile("price", [0.5], 0.01)[0]
mid_list[5] = df.filter(df.area == "同安").approxQuantile("price", [0.5], 0.01)[0]
all_list = []
all_list.append(min_list)
all_list.append(max_list)
all_list.append(mean_list)
all_list.append(mid_list)
print("结束spark分析")
return all_list
然后创建draw.py文件,代码如下:
# -*- coding: utf-8 -*-
from pyecharts import Bar
def draw_bar(all_list):
print("开始绘图")
attr = ["海沧", "湖里", "集美", "思明", "翔安", "同安"]
v0 = all_list[0]
v1 = all_list[1]
v2 = all_list[2]
v3 = all_list[3]
bar = Bar("厦门市租房租金概况")
bar.add("最小值", attr, v0, is_stack=True)
bar.add("最大值", attr, v1, is_stack=True)
bar.add("平均值", attr, v2, is_stack=True)
bar.add("中位数", attr, v3, is_stack=True)
bar.render('./templates/result.html')
print("结束绘图")
这样就完成了爬虫模块的部分。
第二步 flask后台服务端
创建app.py文件。代码如下:
from flask import Flask, render_template
from flask_socketio import SocketIO
from scripts import draw
from scripts import rent_analyse
from scripts import rentspider
def run_spider():
print("开始总程序")
Filename = "rent.csv"
socketio.emit('analyse', {'data':"开始运行爬虫,请等待..."})
rentspider.run()
socketio.emit('analyse', {'data': "结束爬虫"})
socketio.emit('analyse', {'data': "开始分析数据,请等待..."})
all_list = rent_analyse.spark_analyse(Filename)
socketio.emit('analyse', {'data': "结束分析数据"})
socketio.emit('analyse', {'data': "开始绘图,请等待..."})
draw.draw_bar(all_list)
socketio.emit('analyse', {'data': "绘图结束"})
print("结束总程序")
app = Flask(__name__)
app.config['SECRET_KEY'] = 'xmudblab'
socketio = SocketIO(app)
# 客户端访问 http://127.0.0.1:5000/,可以看到index界面
@app.route("/")
def handle_mes():
return render_template("index.html")
# 对客户端发来的start_spider事件作出相应
@socketio.on("start_spider")
def start_spider(message):
print(message)
run_spider()
socketio.emit('get_result', {'data': "请获取最后结果"})
# 对客户端发来的/Get_result事件作出相应
@app.route("/Get_result")
def Get_result():
return render_template("result.html")
if __name__ == '__main__':
socketio.run(app, debug=True)
这里对该部分代码进行相关的解释。
该代码分为两个部分。
程序初始化部分:
app = Flask(__name__)
app.config['SECRET_KEY'] = 'xmudblab'
socketio = SocketIO(app)
if __name__ == '__main__':
socketio.run(app, debug=True)
该部分是flask-socketio程序的常规写法
程序的事件相应部分:
# 客户端访问 http://127.0.0.1:5000/,可以看到index界面
@app.route("/")
def handle_mes():
return render_template("index.html")
# 对客户端发来的start_spider事件作出相应
@socketio.on("start_spider")
def start_spider(message):
print(message)
run_spider()
socketio.emit('get_result', {'data': "请获取最后结果"})
# 对客户端发来的/Get_result事件作出相应
@app.route("/Get_result")
def Get_result():
return render_template("result.html")
这个部分实现了前后端交互时候的后台逻辑。
首先是当客户端访问http://127.0.0.1:5000 时候可以看到index界面。然后通过操作index界面来发送start_spider事件给后台,后台接受到该事件后,运行第一步的爬虫部分程序,并且会利用socket实时向客户端反馈运行进度。当爬虫部分完成后,向客户端发送可以获取结果事件。而@app.route("/Get_result")就是在相应客户端要获取结果。
第三步 客户端部分
创建index.html文件,代码如下:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>FishRent</title>
<script src="static/js/socket.io.js"></script>
<script src="static/js/jquery-3.1.1.min.js"></script>
<script type="text/javascript" charset="utf-8">
$(document).ready(function() {
var socket = io.connect(location.protocol + '//' + document.domain + ':' + location.port);
//连接后发送日志
socket.on('connect', function(){
console.log('connected')
});
//断开后发送日志
socket.on('disconnect', function () {
console.log('disconnect');
});
//点击开始后,执行程序
$('#btn').click(function() {
socket.emit('start_spider', {data: 'Start spider'});
});
//接收后端发送的提示消息
socket.on('analyse', function(msg) {
var obj = eval(msg);
var result = obj["data"];
$('#log').append('<br>' + result);
});
//收到后台可以获取最终结果的消息后,新增按钮,点击可以获取结果
socket.on('get_result', function(msg) {
var obj = eval(msg);
var result = obj["data"];
$('#log').append('<br>' + result);
$('#cnt').append("<br> <button id=\"get_res\">获取结果</button>");
$('#get_res').click(function() {
//在当前窗口打开界面
window.open('/Get_result')
//在新窗口打开界面,二者选一个就好
//window.location.href = '/Get_result'
});
});
});
</script>
</head>
<body>
<div id="cnt">
<button id="btn">开始爬虫</button>
<h4 id="log"></h4>
</div>
</body>
</html>
index界面开始只有一个开始爬虫按钮,点击后向后台发送start_spider事件。然后会实时展示后台的爬虫运行进度。收到爬虫结束事件后,会增加一个获取结果按钮。点击可查看最后结果。该部分会用到js文件夹下的三个文件,jquery-3.1.1.min.js,socket.io.js,以及socket.io.js.map。这些都可以从网上下载。文章的最后也会提供完整的程序工程文件压缩包,也可以从里面获得。
运行程序
在pycharm里面运行app.py,开启后台服务。然后在浏览器访问http://127.0.0.1:5000/ 可以看到index界面,只有一个开始爬虫分析按钮。点击开始运行。运行过程如图。
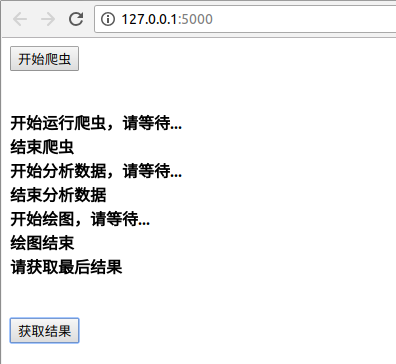
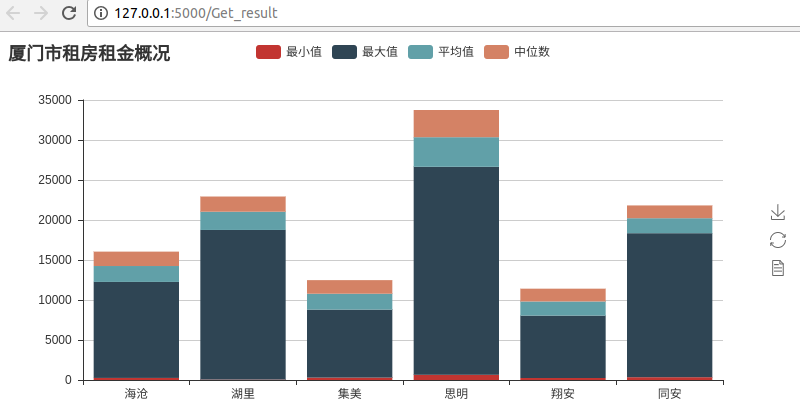
点击获取结果按钮,可以看到最终结果。
最后附上工程文件压缩包。
点击下载压缩包