

点击这里观看厦门大学林子雨老师主讲《大数据技术原理与应用》授课视频
【版权声明】博客内容由厦门大学数据库实验室拥有版权,未经允许,请勿转载!
[返回Spark教程首页]
对Scala代码进行打包编译时,可以采用Maven,也可以采用sbt,相对而言,业界更多使用sbt。本教程介绍如何在 Ubuntu中使用 Eclipse 来开发 scala 程序(使用Maven工具),在Spark 2.1.0,scala 2.11.8 下验证通过。使用 Eclipse,我们可以直接运行代码,省去许多繁琐的命令。(相关文章:如何在 Ubuntu中使用 Eclipse 来开发 scala 程序(使用sbt工具))
一.运行环境介绍
Scala ide for eclipse
ubuntu 16.04
spark 2.1.0
scala 2.11
二.安装必备软件
Spark和scala安装方法可以参考,Spark安装和使用 ,Scala安装,
eclipse可以安装scala ide for eclipse,这样可以省下很多工夫去不用安装maven和scala类似的相关插件,进入scala ide for eclipse,图如下所示,选择Linux GTK 64 bit,
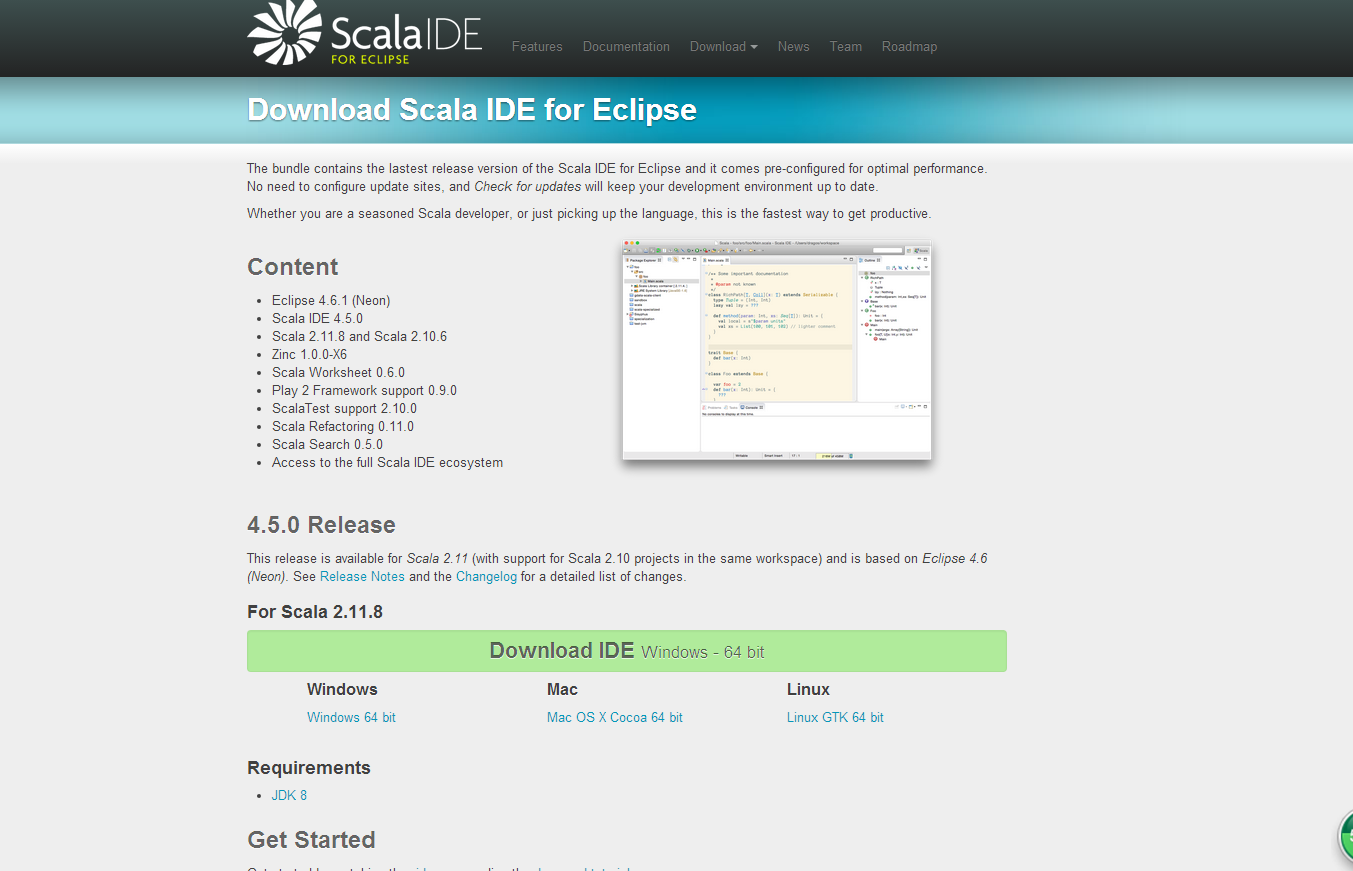
接下来解压安装包到/usr/local下,并测试运行eclipse
sudo tar -zxvf ~/下载/scala-SDK-4.5.0-vfinal-2.11-linux.gtk.x86_64.tar.gz -C /usr/local
cd /usr/local
./eclipse/eclipse
出现如下界面说明运行成功了。

如果各位没有安装该版本的eclipse,很可能会花费不必要的麻烦去安装相关的插件,下面笔者也介绍下安装maven和scala插件的方法,(ps:安装了scala ide for eclipse的可以直接跳过该步骤)
安装maven插件和scala插件
先进入eclipse后,点击Help-->Install New Software,在出现的install界面上输入maven插件的网址,http://download.eclipse.org/releases/neno (注意:末尾的neno是eclipse对应的版本名称,如果你用的不是neno版本,请换成自己用的eclipse版本号),然后再在下面的文本框输入maven,点击select all,点击next,接下来一直点击next或finish就可以了。
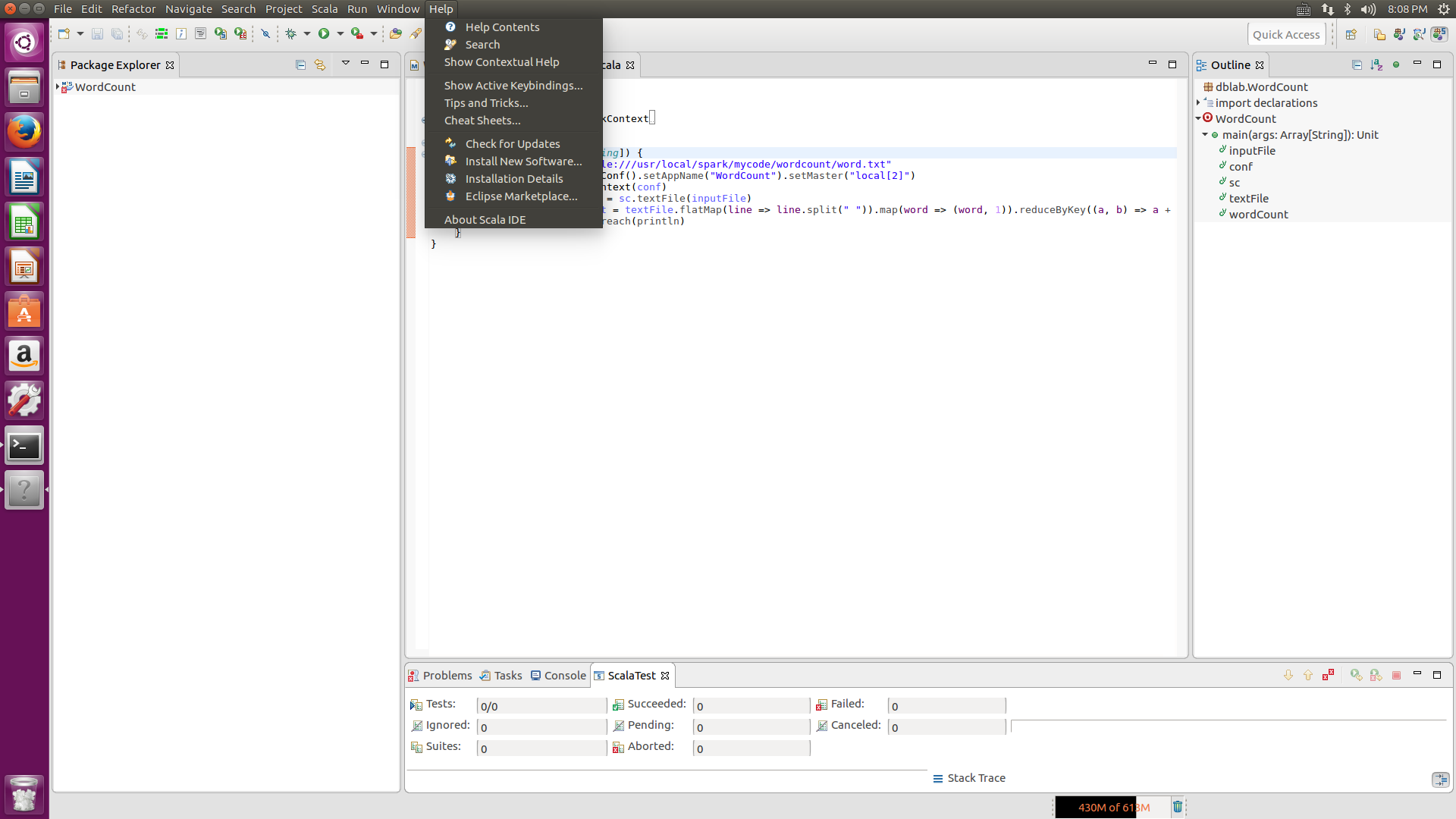
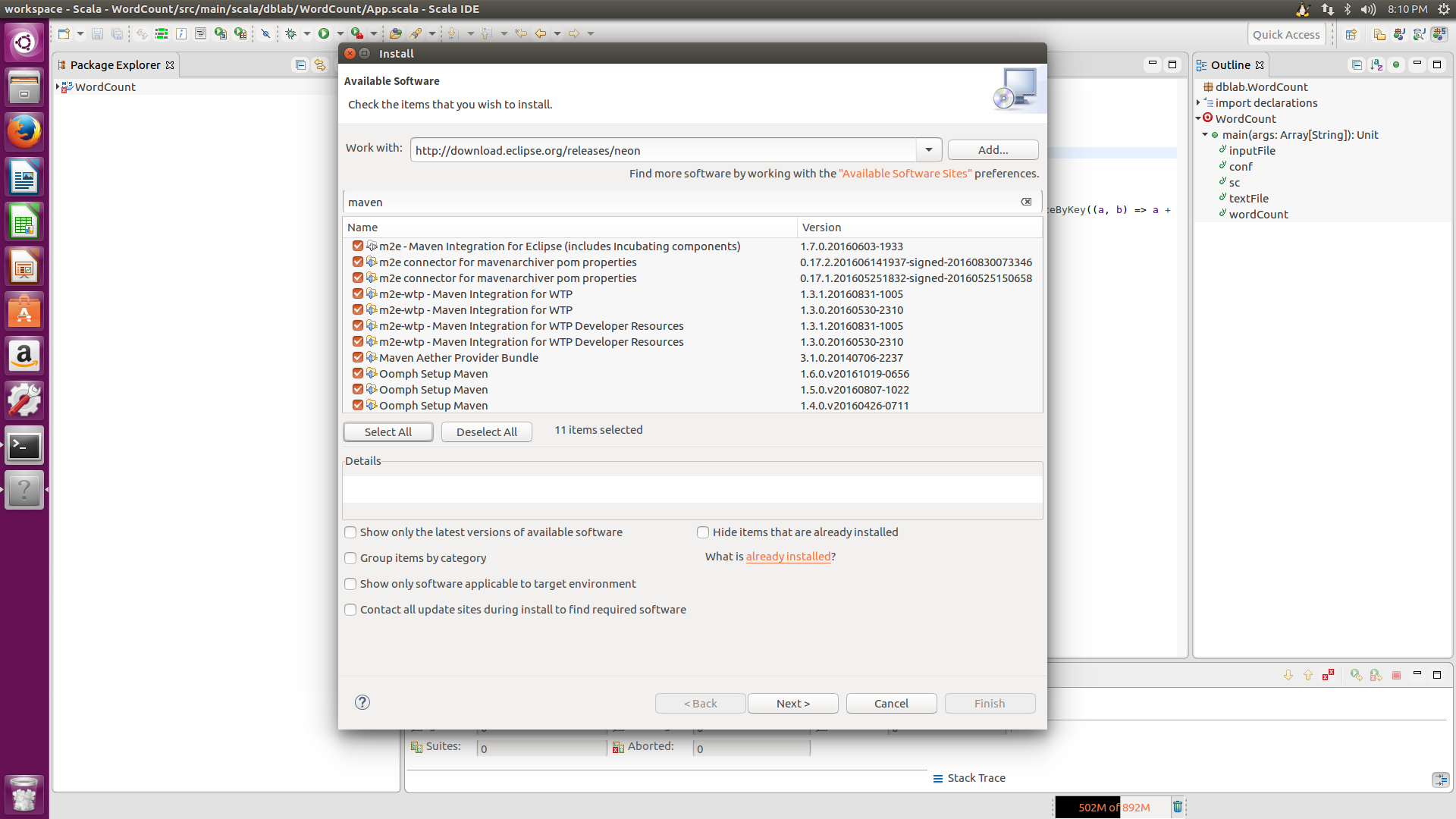
安装scala插件同样,点击Help-->Install New Software,在出现的install界面上输入scala插件的网址, http://download.scala-ide.org/sdk/helium/e38/scala211/stable/site ,摁下回车键,接着select all,然后同样一直next或finish就可以了。

在/usr/local/spark下建立目录/mycode/wordcount,然后在“/usr/local/spark/mycode/wordcount”目录下新建一个包含了一些语句的文本文件word.txt,命令如下:
cd /usr/local/spark
mkdir mycode
cd mycode
mkdir wordcount
cd wordcount
vim word.txt
你可以在文本文件中随意输入一些单词,用空格隔开,我们会编写Spark程序对该文件进行单词词频统计。然后,按键盘Esc键退出vim编辑状态,输入“:wq”保存文件并退出vim编辑器。
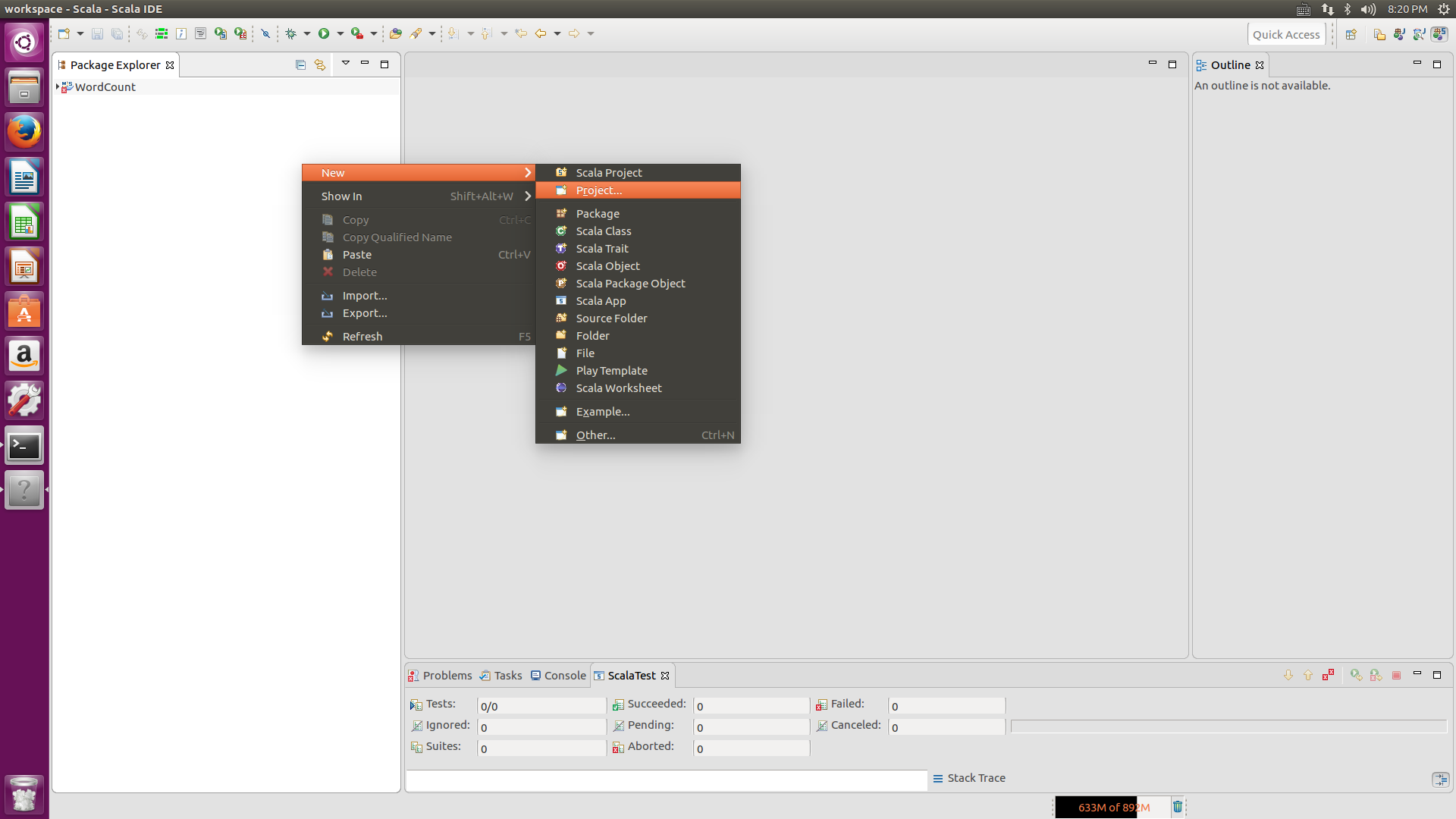
三.创建maven工程
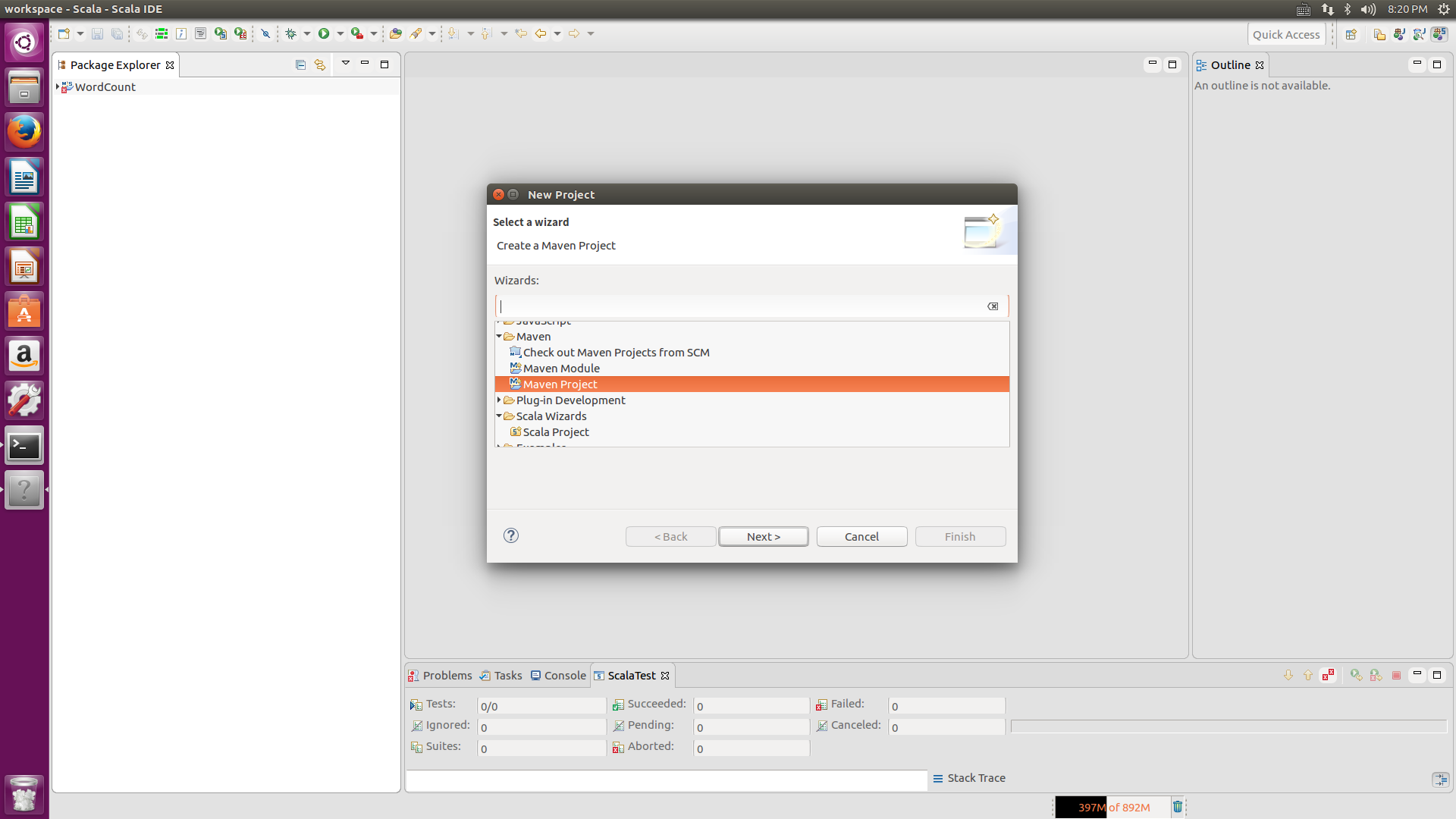
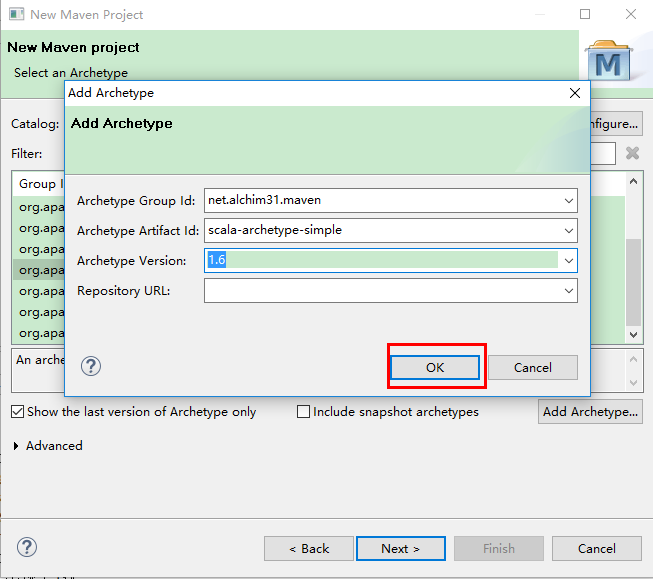
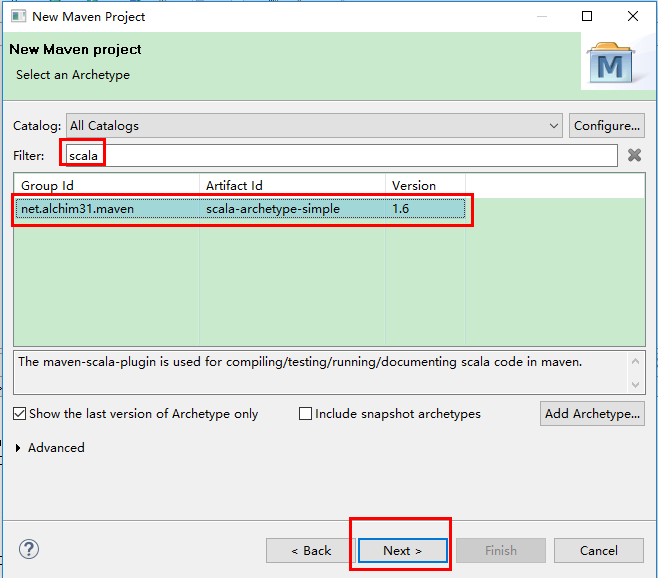
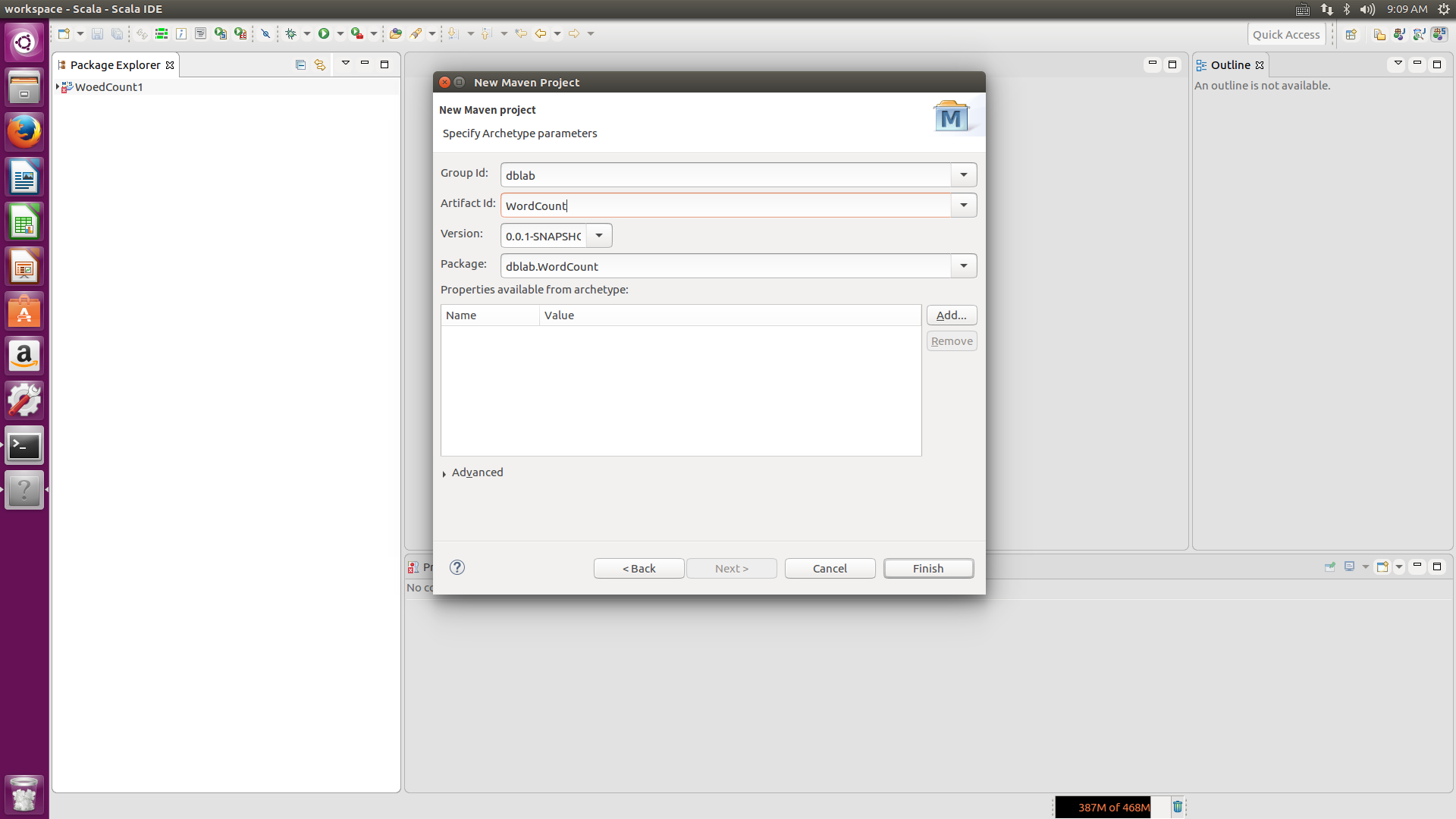
打开eclipse后,在工程栏右键New-->Project,在出现的界面上双击maven文件,选择maven project,先点击右下角的Add Archetype,第一个Archetype Group id 选择net.alchim31.maven,第二个Archetype Artifact id选择scala-archetype-simple,第三个选择version是1.6,点击OK,在Catalog里选择All Catalogs,在filter里输入scala,会出现net.alchim31.maven,version为1.6版本的选项,选择它,点击next,然后在Groupid上填写dblab,在Artifact填写WordCount,package填写dblab.WordCount,点击Finish。这样就可以在maven上创建Scala类了。
四.创建scala类,运行scala程序
点击新建的WordCount工程,再选择src/main/scala,右击dblab.WordCount那个建成的包,New-->scala Class,然后在Name那个文本框中输入dblab.WordCount.WordCount,点击Finish,

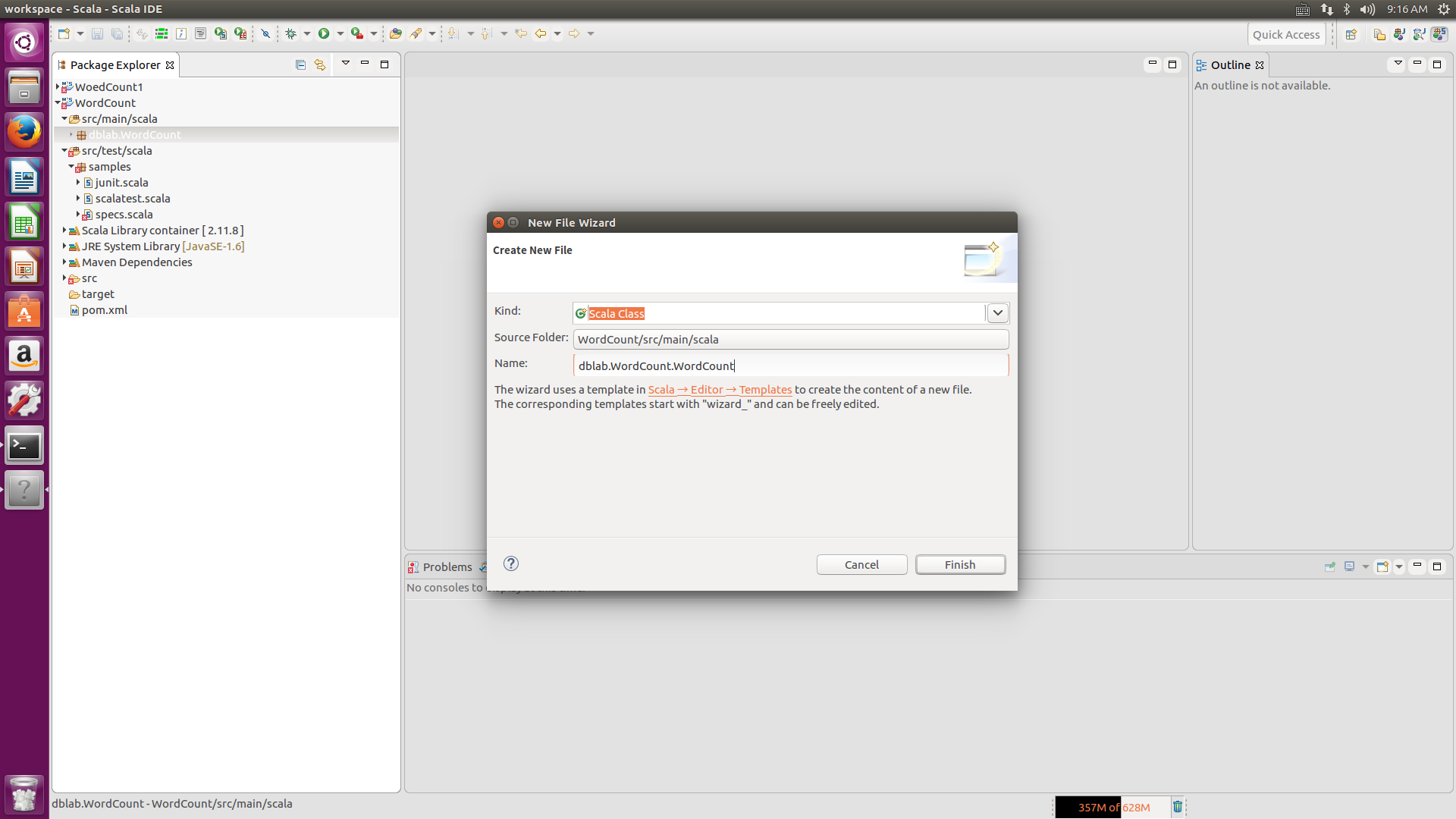
然后将如下代码完全复制进去
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf
object WordCount {
def main(args: Array[String]) {
val inputFile = "file:///usr/local/spark/mycode/wordcount/word.txt"
val conf = new SparkConf().setAppName("WordCount").setMaster("local[2]")
val sc = new SparkContext(conf)
val textFile = sc.textFile(inputFile)
val wordCount = textFile.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey((a, b) => a + b)
wordCount.foreach(println)
}
}
接下来编译pom.xml文件,把代码运行的包导入环境中,如图
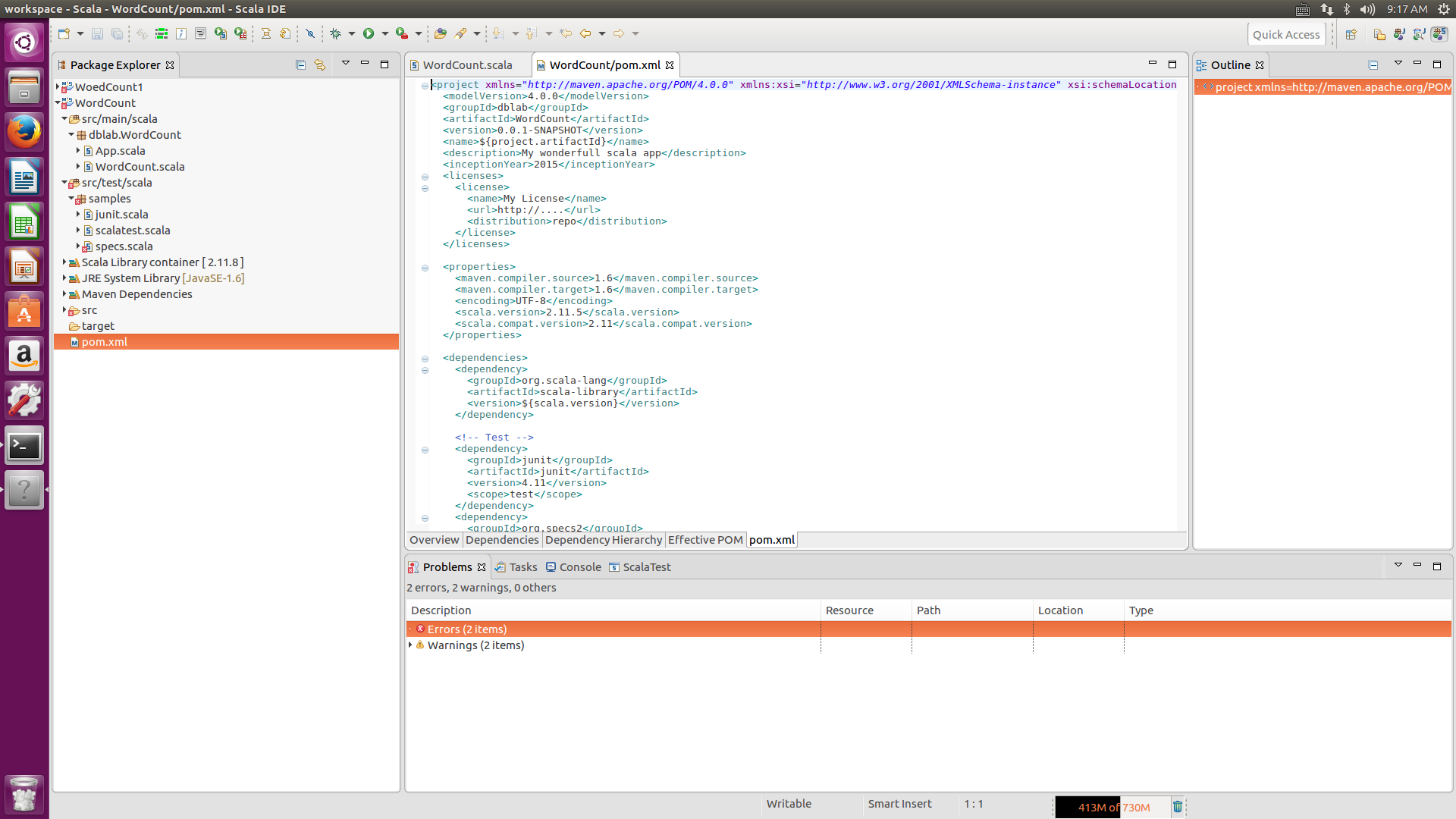
然后将pom.xml里的内容清空,复制黏贴如下代码
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>dblab</groupId>
<artifactId>WordCount</artifactId>
<version>0.0.1-SNAPSHOT</version>
<inceptionYear>2008</inceptionYear>
<properties>
<scala.version>2.11</scala.version>
<spark.version>2.1.0</spark.version>
</properties>
<repositories>
<repository>
<id>scala-tools.org</id>
<name>Scala-Tools Maven2 Repository</name>
<url>http://scala-tools.org/repo-releases</url>
</repository>
</repositories>
<pluginRepositories>
<pluginRepository>
<id>scala-tools.org</id>
<name>Scala-Tools Maven2 Repository</name>
<url>http://download.eclipse.org/releases/indigo/</url>
</pluginRepository>
</pluginRepositories>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.4</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.specs</groupId>
<artifactId>specs</artifactId>
<version>1.2.5</version>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<testSourceDirectory>src/test/scala</testSourceDirectory>
<plugins>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
<configuration>
<scalaVersion>${scala.version}</scalaVersion>
<args>
<arg>-target:jvm-1.5</arg>
</args>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-eclipse-plugin</artifactId>
<configuration>
<downloadSources>true</downloadSources>
<buildcommands>
<buildcommand>ch.epfl.lamp.sdt.core.scalabuilder</buildcommand>
</buildcommands>
<additionalProjectnatures>
<projectnature>ch.epfl.lamp.sdt.core.scalanature</projectnature>
</additionalProjectnatures>
<classpathContainers>
<classpathContainer>org.eclipse.jdt.launching.JRE_CONTAINER</classpathContainer>
<classpathContainer>ch.epfl.lamp.sdt.launching.SCALA_CONTAINER</classpathContainer>
</classpathContainers>
</configuration>
</plugin>
</plugins>
</build>
<reporting>
<plugins>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<configuration>
<scalaVersion>${scala.version}</scalaVersion>
</configuration>
</plugin>
</plugins>
</reporting>
</project>
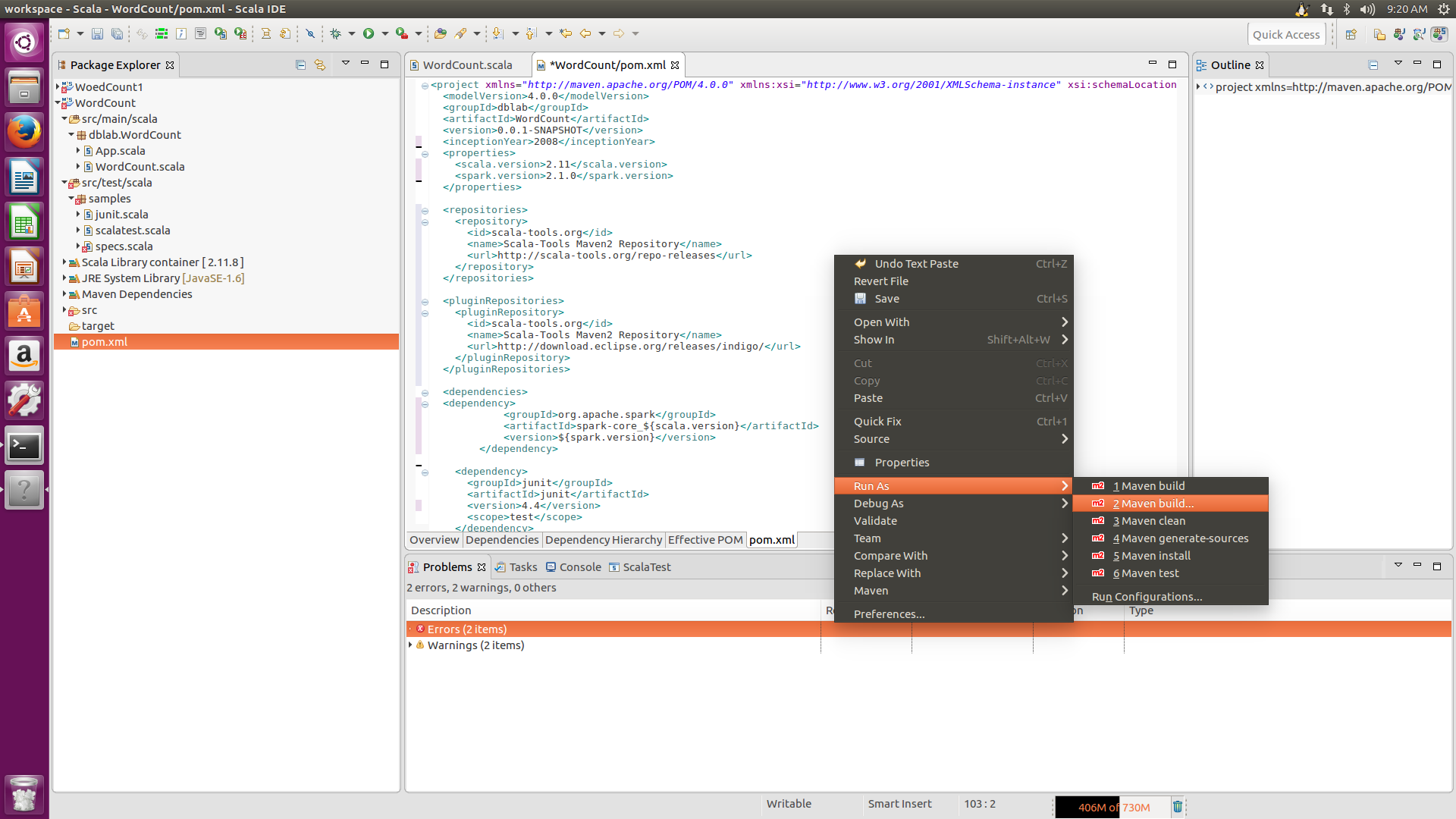
在代码处右击,Run AS-->Maven build,编译,如果在Console栏里出现Build success,说明编译成功
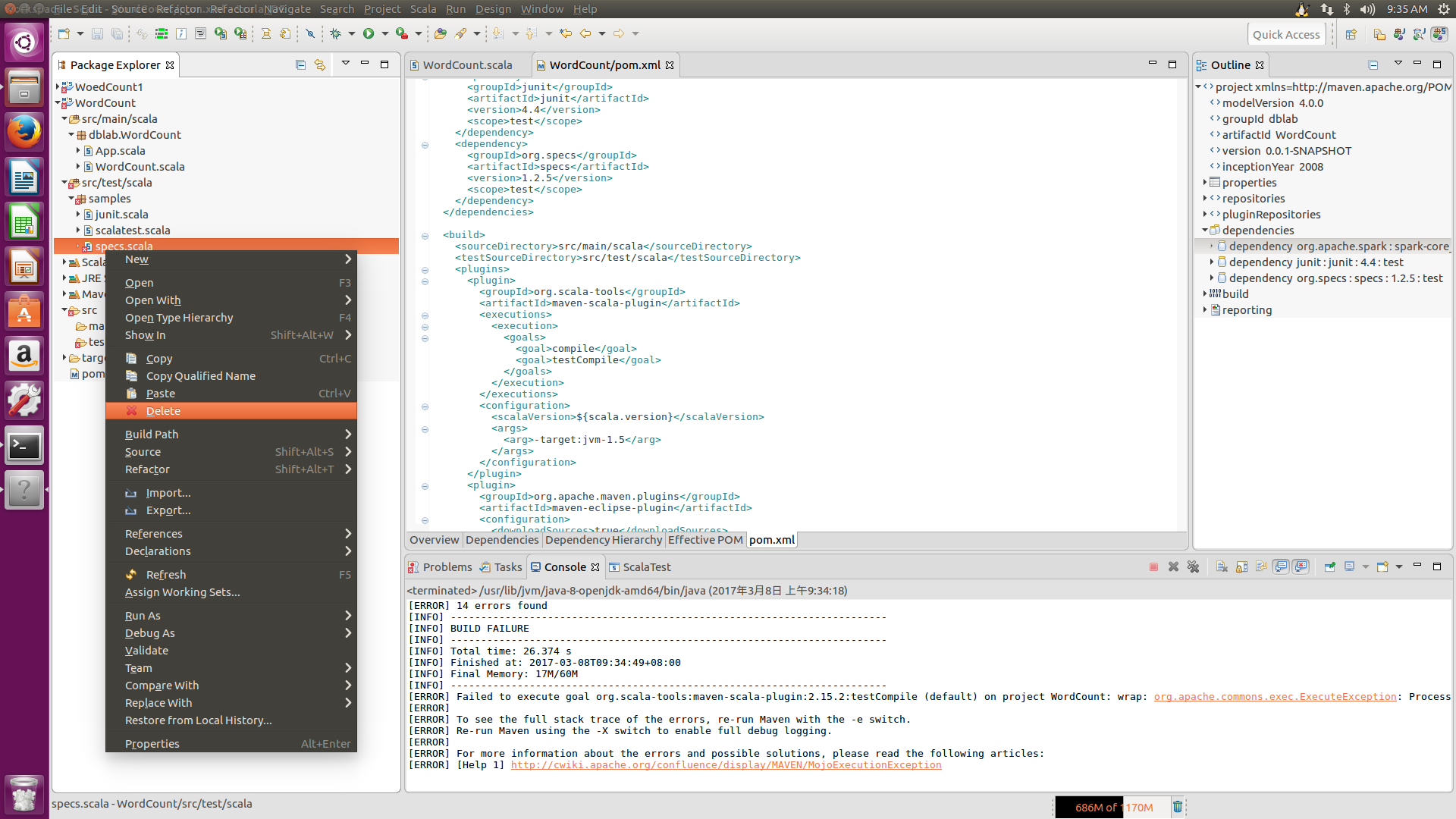
回到scala程序界面,你会发现左边第二个src/test/scala文件有个小红叉,这个对编译结果并没影响,但会影响后面打包,可以删除它
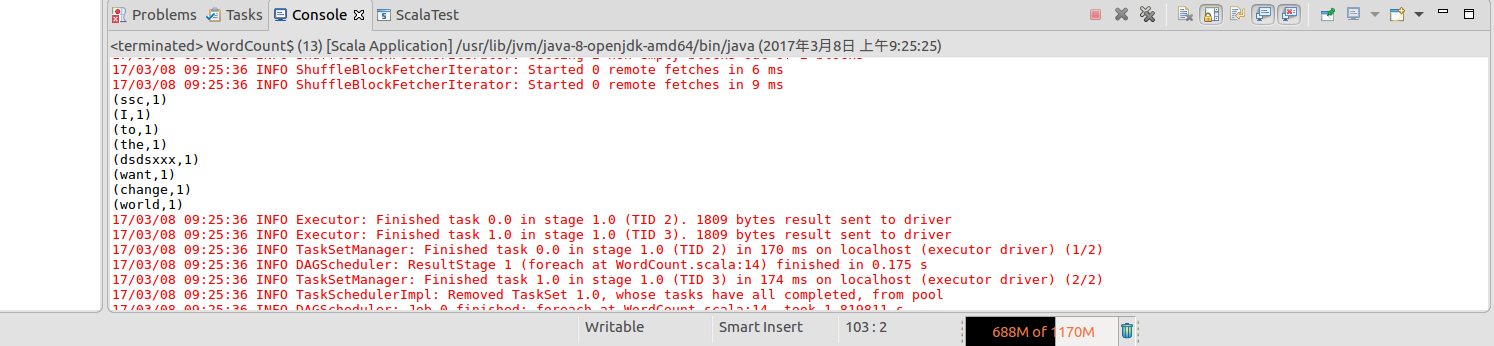
继续右击WordCount.scala.Run AS -->scala Application,得出结果
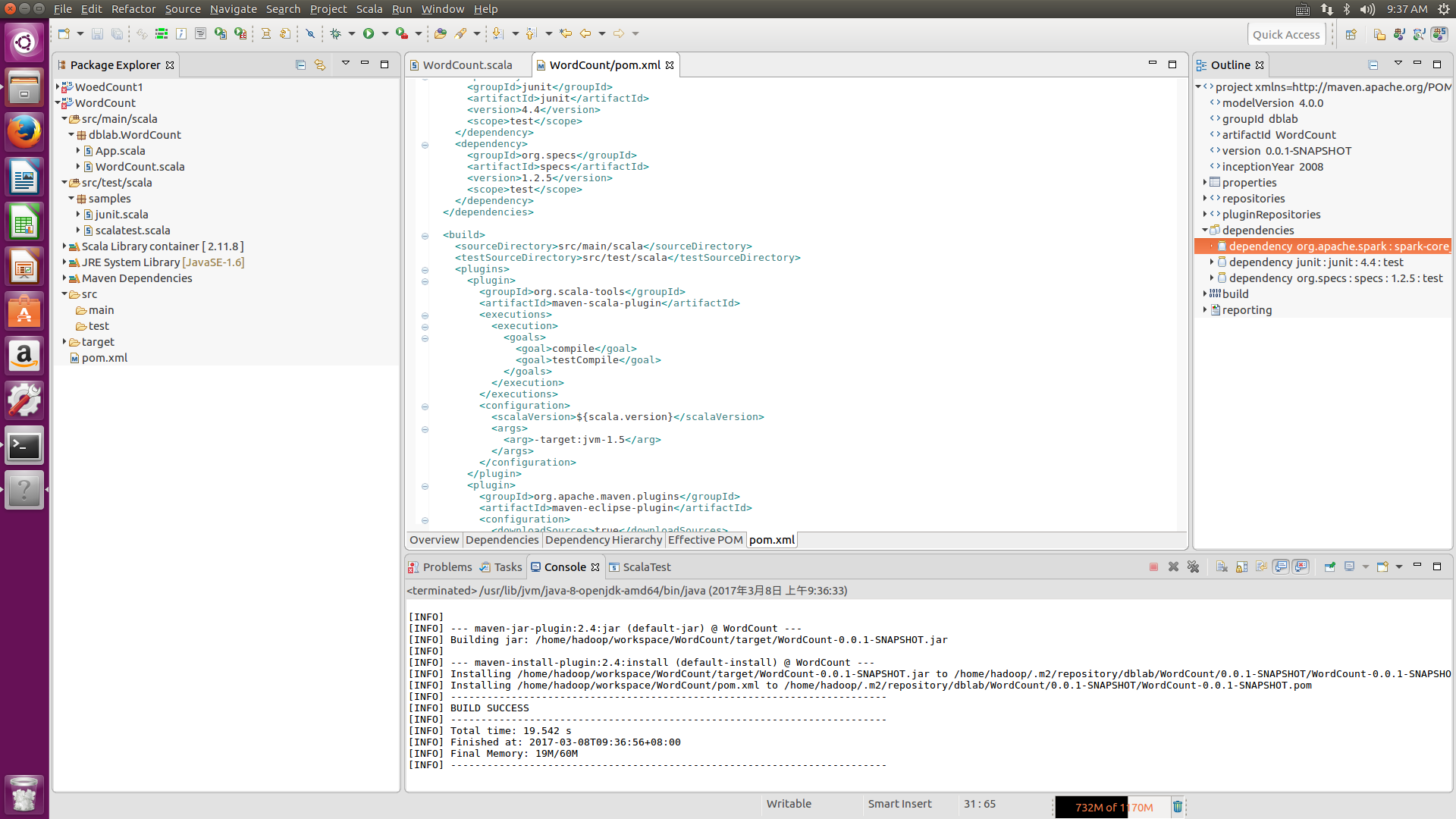
接着我们返回pom.xml的界面,空白处右击,Run AS-->Maven install,出现如下界面后说明打包已成功,
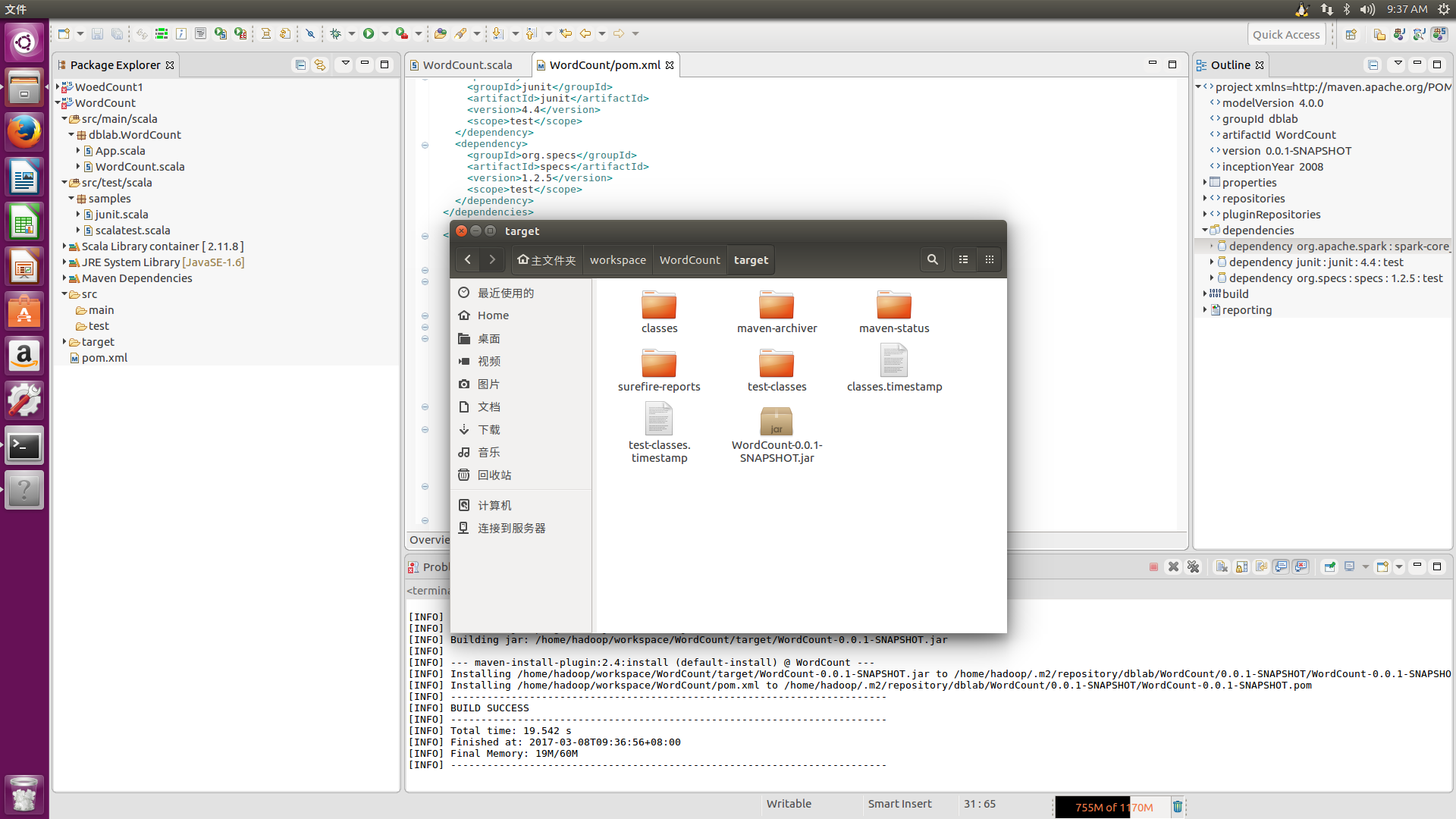
打开Ubuntu自带的文件夹系统,进入/home/hadoop/workspace/WordCount/target,会看到WordCount-0.0.1-SNAPSHOT.jar,就是maven打包成功的文件
然后,由于Ubuntu系统的原因,包的路径太深,运行很可能会出现找不到类的异常,所以我们可以把这个包移动到常用的较浅的目录下,
sudo cp /home/hadoop/workspace/WordCount/target/WordCount-0.0.1-SNAPSHOT.jar /usr/local #/usr/local是本人常用的目录
接着我们运行以下指令,
/usr/local/spark/bin/spark-submit --class "WordCount" /usr/local/WordCount-0.0.1-SNAPSHOT.jar
出现如下结果,就说明你在终端下已经成功运行了scala的WordCount程序


