林子雨编著《大数据基础编程、实验和案例教程》(教材官网)教材中的代码,在纸质教材中的印刷效果不是很好,可能会影响读者对代码的理解,为了方便读者正确理解代码或者直接拷贝代码用于上机实验,这里提供全书配套的所有代码。
查看教材所有章节的代码
继续阅读
林子雨编著《大数据基础编程、实验和案例教程》教材第2章的代码
林子雨编著《大数据基础编程、实验和案例教程》(教材官网)教材中的代码,在纸质教材中的印刷效果不是很好,可能会影响读者对代码的理解,为了方便读者正确理解代码或者直接拷贝代码用于上机实验,这里提供全书配套的所有代码。
查看教材所有章节的代码
继续阅读
Spark大数据分析案例之平均心率检测
案例介绍
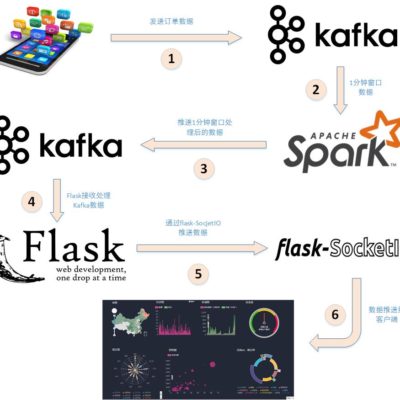
平均心率检测案例。本案例以实验室之前发布的另一篇博客文章《Spark+Kafka构建实时分析Dashboard案例介绍》为基础,涉及模拟数据生成,数据预处理、消息队列发送和接收消息、数据实时处理、数据实时推送和实时展示等数据处理全流程,所涉及的各种典型操作涵盖Linux、Spark、Kafka、JAVA、MySQL、Ajax、Html、Css、Js、Maven等系统和软件的安装和使用方法。通过本案例,将有助于综合运用大数据课程知识以及各种工具软件,实现数据全流程操作。同时在此感谢张少坤、吴维奇和喻小丽等三位同学在创作本案例中的贡献。
继续阅读
Spark+Kafka构建实时分析Dashboard案例——步骤四:结果展示
返回本案例首页
查看前一步骤操作:步骤三:Spark Streaming实时处理数据
《Spark+Kafka构建实时分析Dashboard案例——步骤四:结果展示》
开发团队:厦门大学数据库实验室 联系人:林子雨老师ziyulin@xmu.edu.cn
版权声明:版权归厦门大学数据库实验室所有,请勿用于商业用途;未经授权,其他网站请勿转载
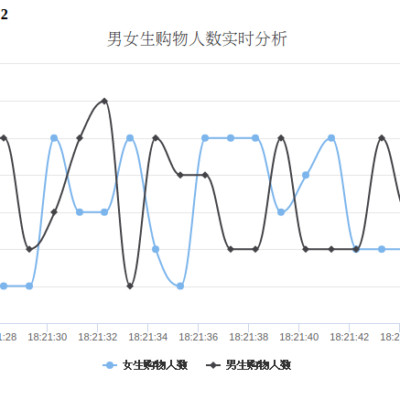
本教程介绍大数据课程实验案例“Spark+Kafka构建实时分析Dashboard”的第四个步骤,结果展示。在本篇博客中,将介绍如何利用Flask-SocketIO向客户端发送消息以及客户端如何利用highcharts.js展示数据。
Spark+Kafka构建实时分析Dashboard案例——步骤三:Spark Streaming实时处理数据

查看前一步骤操作步骤二:数据处理和Python操作Kafka
《Spark+Kafka构建实时分析Dashboard案例——步骤三:Spark Streaming实时处理数据》
开发团队:厦门大学数据库实验室 联系人:林子雨老师ziyulin@xmu.edu.cn
版权声明:版权归厦门大学数据库实验室所有,请勿用于商业用途;未经授权,其他网站请勿转载
本教程介绍大数据课程实验案例“Spark+Kafka构建实时分析Dashboard”的第三个步骤,Spark Streaming实时处理数据。在本篇博客中,将介绍如何利用Spark Streaming实时接收处理Kafka数据以及将处理后的结果发给的Kafka。
Spark+Kafka构建实时分析Dashboard案例——步骤二:数据处理和Python操作Kafka
返回本案例首页
查看前一步骤操作步骤一:实验环境准备
《Spark+Kafka构建实时分析Dashboard案例——步骤二:案例介绍》
开发团队:厦门大学数据库实验室 联系人:林子雨老师ziyulin@xmu.edu.cn
版权声明:版权归厦门大学数据库实验室所有,请勿用于商业用途;未经授权,其他网站请勿转载
本教程介绍大数据课程实验案例“Spark+Kafka构建实时分析Dashboard”的第二个步骤,数据处理和Python操作Kafka。在本篇博客中,首先介绍如何预处理数据,以及如何使用Python操作Kafka。
Spark+Kafka构建实时分析Dashboard案例——步骤一:实验环境准备

Spark+Kafka构建实时分析Dashboard案例介绍
Redis安装和使用(Ubuntu系统)
本节内容包括Redis简介、安装Redis和Redis实例演示等,Redis在Window系统安装教程可参考https://dblab.xmu.edu.cn/blog/131/#more-131
Spark2.1.0入门:模型选择和超参数调整
【版权声明】博客内容由厦门大学数据库实验室拥有版权,未经允许,请勿转载!
[返回Spark教程首页]
## 模型选择和超参数调整
在机器学习中非常重要的任务就是模型选择,或者使用数据来找到具体问题的最佳的模型和参数,这个过程也叫做调试(Tuning)。调试可以在独立的估计器中完成(如逻辑斯蒂回归),也可以在包含多样算法、特征工程和其他步骤的工作流中完成。用户应该一次性调优整个工作流,而不是独立的调整PipeLine中的每个组成部分。
继续阅读