返回《在阿里云中搭建大数据实验环境》首页
提示:本教程是一个系列文章,请务必按照本教程首页中给出的各个步骤列表,按照先后顺序一步步进行操作,本博客假设你已经顺利完成了之前的操作步骤。
现在介绍在在ECS实例的Ubuntu系统中安装ScalaIDE。
为什么要使用Scala IDE for Eclipse
Eclipse是一款流行的开发工具,如果要使用Eclipse开发Scala程序,就需要为Eclipse安装Scala插件、Maven插件和sbt插件,安装这些插件的过程十分繁琐、耗时、痛苦,而且,即使安装成功,过一段时间,也会因为插件依赖的网站失效,而导致无法运行。笔者就被这个问题困扰过。所以,后来下定决心使用ScalaIDE(scala ide for eclipse)。ScalaIDE自身就是在Eclipse基础上开发的,里面集成了Eclipse、Scala插件、Maven插件和sbt插件,不用费时费力去安装这些插件,也不会发生插件失效的问题。
下载和安装Scala IDE for Eclipse
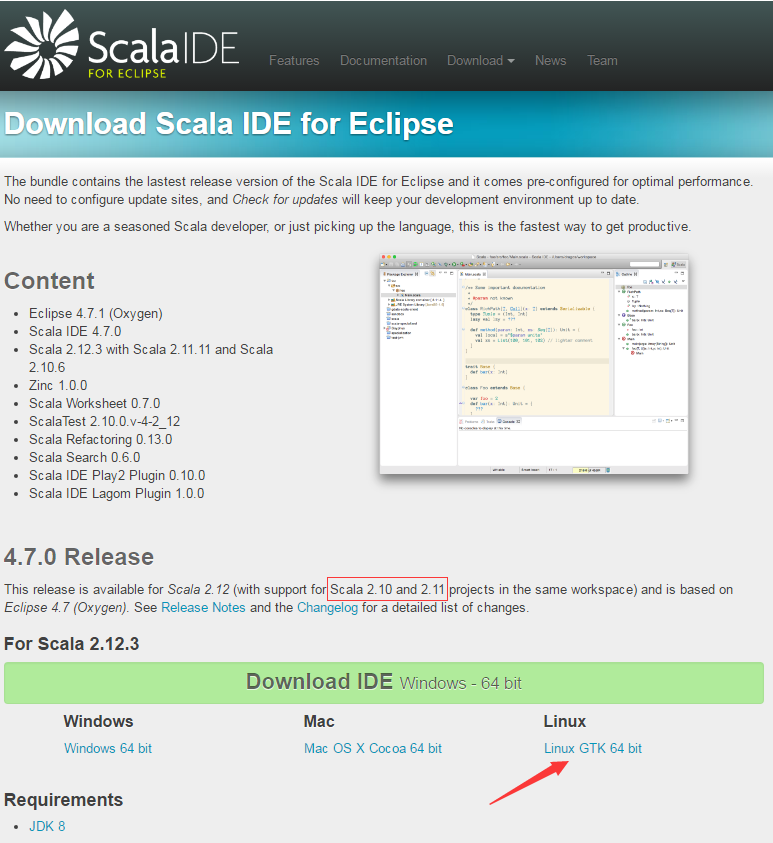
进入Scala IDE for Eclipse官网,选择Linux GTK 64 bit,下载到自己的笔记本电脑中。
或者,也可以直接在自己的笔记本电脑中,点击这里访问百度云盘下载scala-SDK-4.7.0-vfinal-2.12-linux.gtk.x86_64.tar.gz文件(提取码:gx0b),下载到自己笔记本电脑,然后使用FTP软件上传到阿里云ECS实例的Ubuntu系统的“/home/linziyu/Downloads”目录下(点击这里阅读FTP连接ECS的方法)。
接下来,在自己的笔记本电脑中,使用VNC Viewer软件连接到阿里云ECS实例的Ubuntu系统(阅读VNC使用方法),在远程的Ubuntu系统中打开一个命令行终端(假设当前登录用户为linziyu),然后,执行如下命令解压安装包到/usr/local下,并测试运行Eclipse:
cd ~
sudo tar -zxvf ~/Downloads/scala-SDK-4.7.0-vfinal-2.12-linux.gtk.x86_64.tar.gz -C /usr/local
cd /usr/local
ls #可以看到当前目录下已经出现一个eclipse子目录
cd eclipse
./eclipse
然后,会弹出如下界面,请在界面中点击“Launch”按钮。
然后,Eclipse会启动进入如下工程开发界面:

创建Maven工程
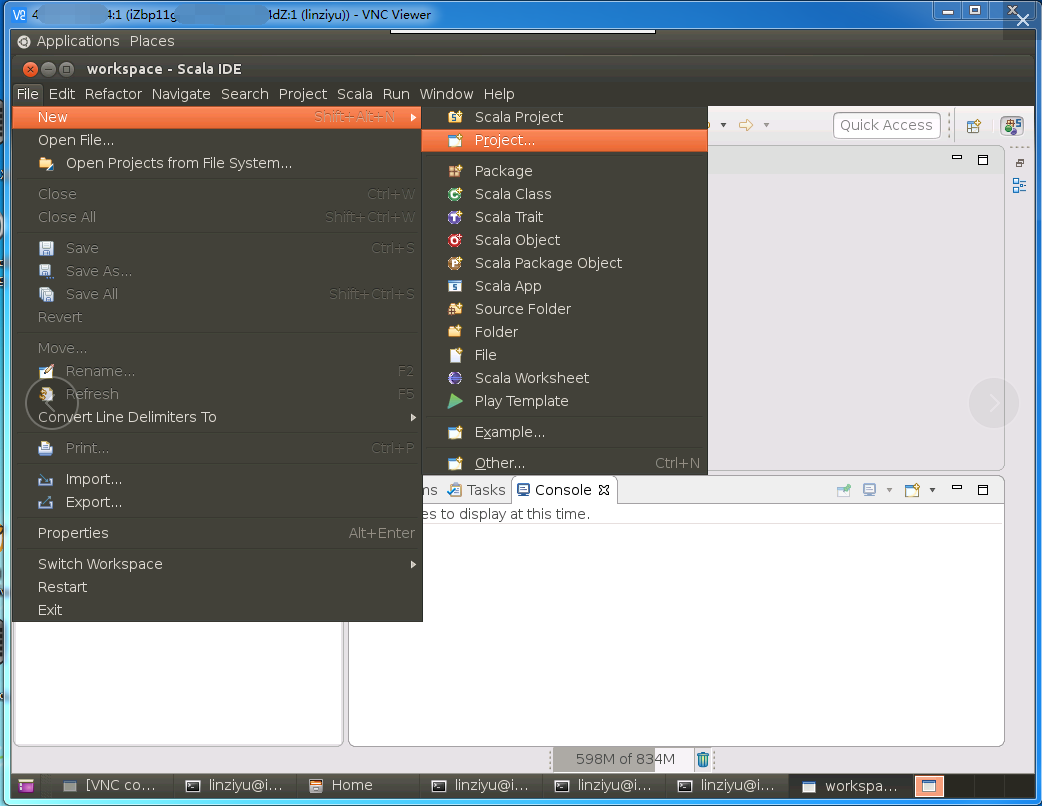
打开Eclipse后,在工程的顶部菜单栏,选择“File-->New-->Project”,如下图所示:
在出现的界面上(如下图所示)点击Maven文件夹,选择Maven Project,然后,点击“Next”按钮。
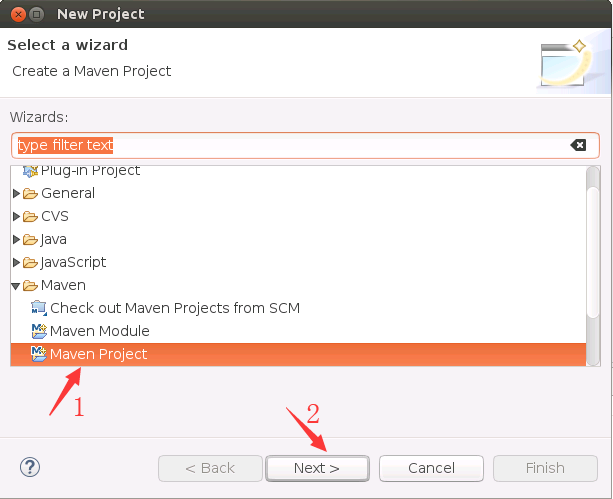
然后,弹出如下界面,直接点击“Next”按钮。
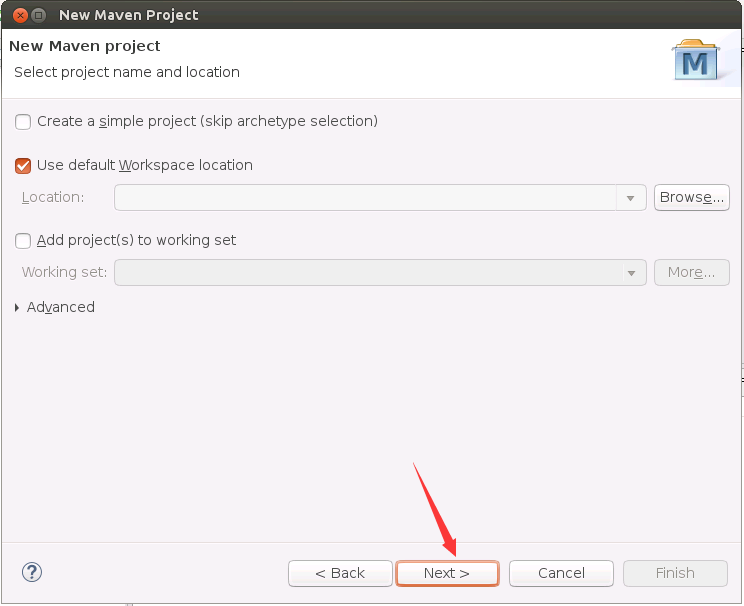
然后,在弹出的界面中(如下图所示),点击右下角的Add Archetype按钮。
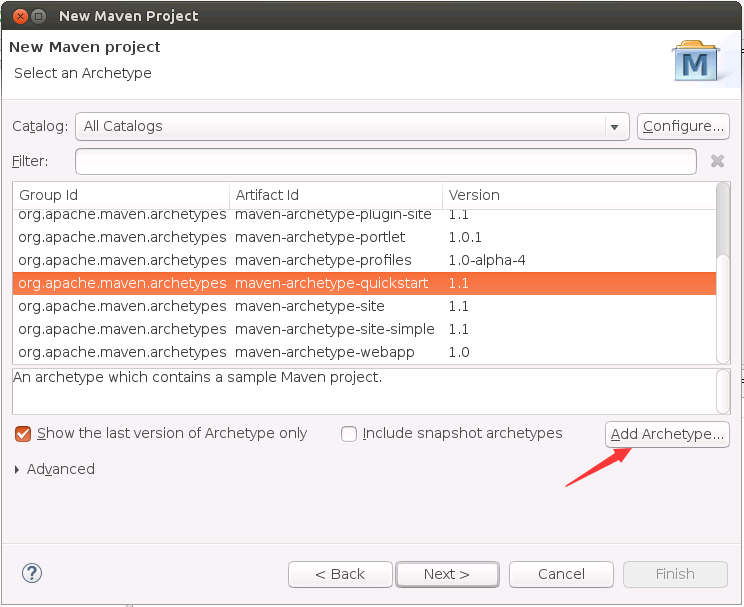
然后,在弹出的界面中(如下图所示),第一个是Archetype Group id,右边是一个下拉列表框,可以点击右侧的向下的小三角形按钮,展开下拉列表,在下拉列表框中选择net.alchim31.maven,第二个Archetype Artifact id,在下拉列表框中选择scala-archetype-simple,第三个选择version是1.6,点击OK按钮。
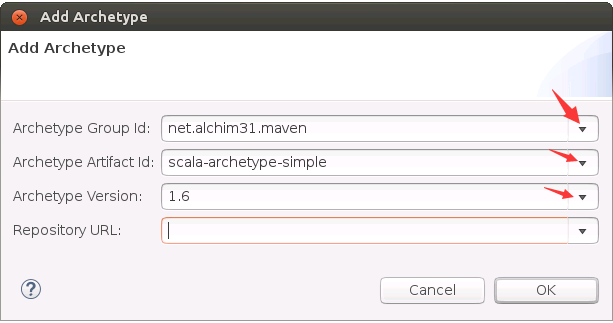
然后,在弹出的界面中(如下图所示),在Catalog这个下拉列表框中选择All Catalogs,在filter后面的文本框中里输入scala,会出现net.alchim31.maven,version为1.6版本的选项,选中它,然后,点击“Next”按钮。
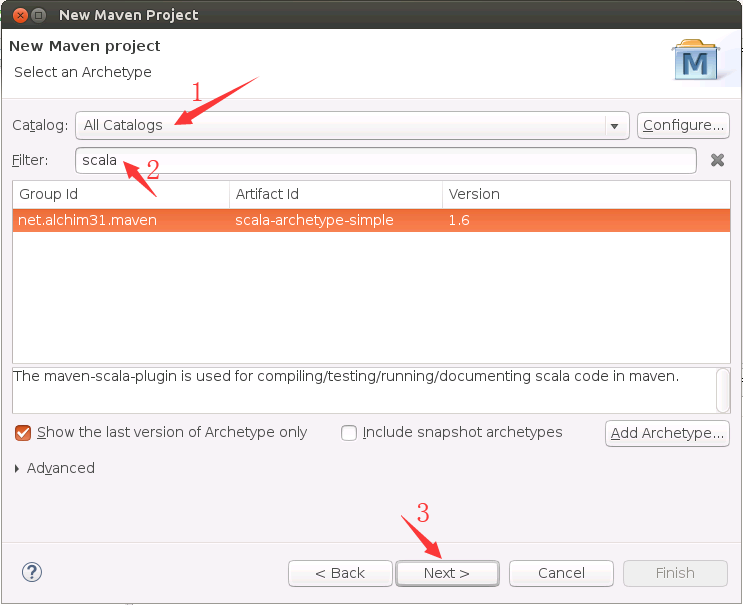
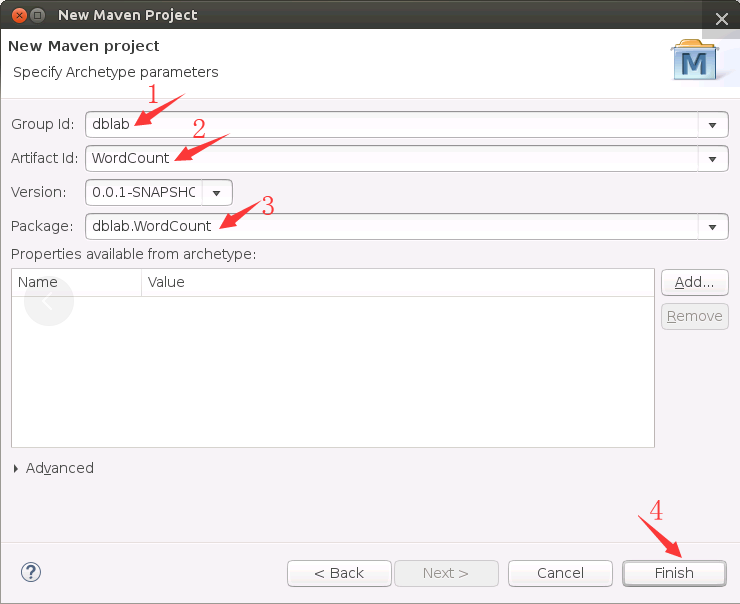
然后,弹出如下界面,在Groupid上填写dblab,在Artifact填写WordCount,package填写dblab.WordCount,点击Finish按钮。这样就可以在Maven上创建Scala类了。
更换Scala库和JDK
然后,会返回到工程界面。注意,在界面左侧的WordCount工程目录树中,可以看到,Scala版本是2.12.3,不符合我们的要求,我们要求是Scala2.11.8,所以需要更换。
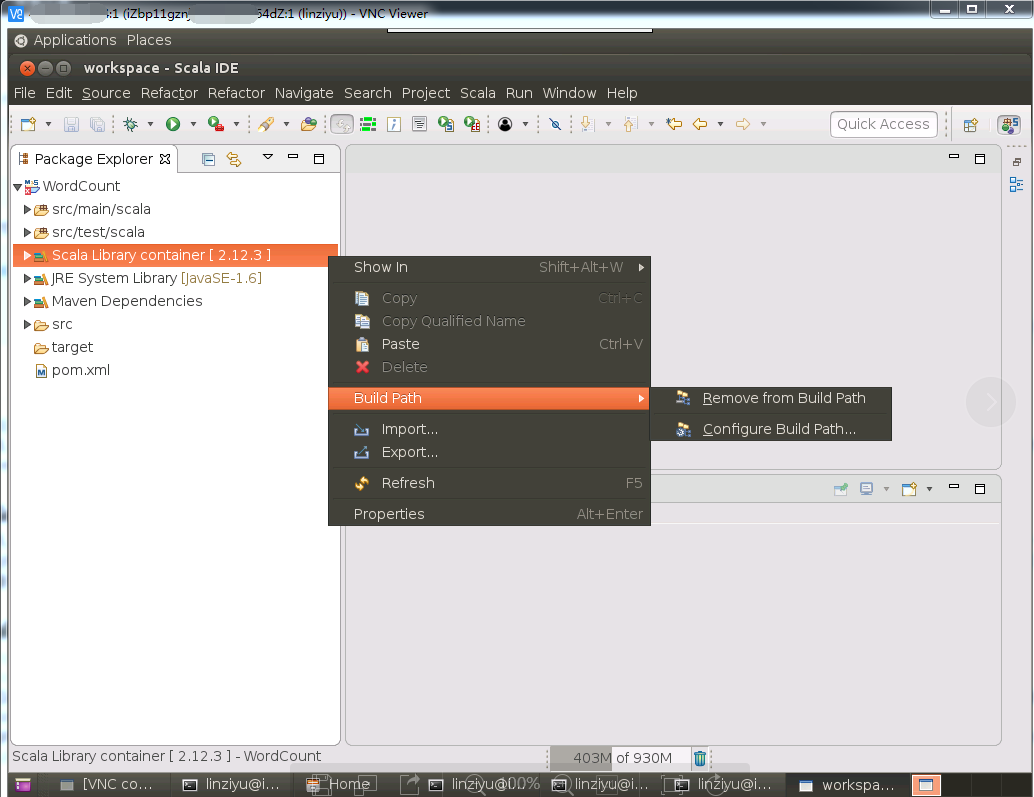
首先,如下图所示,在“Scala Library Container[2.12.3]”上面单击鼠标右键,在弹出的菜单中选择“Build Path”,在弹出的子菜单中选择“Remove from Build Path”,删除Scala2.12.3版本的库文件。
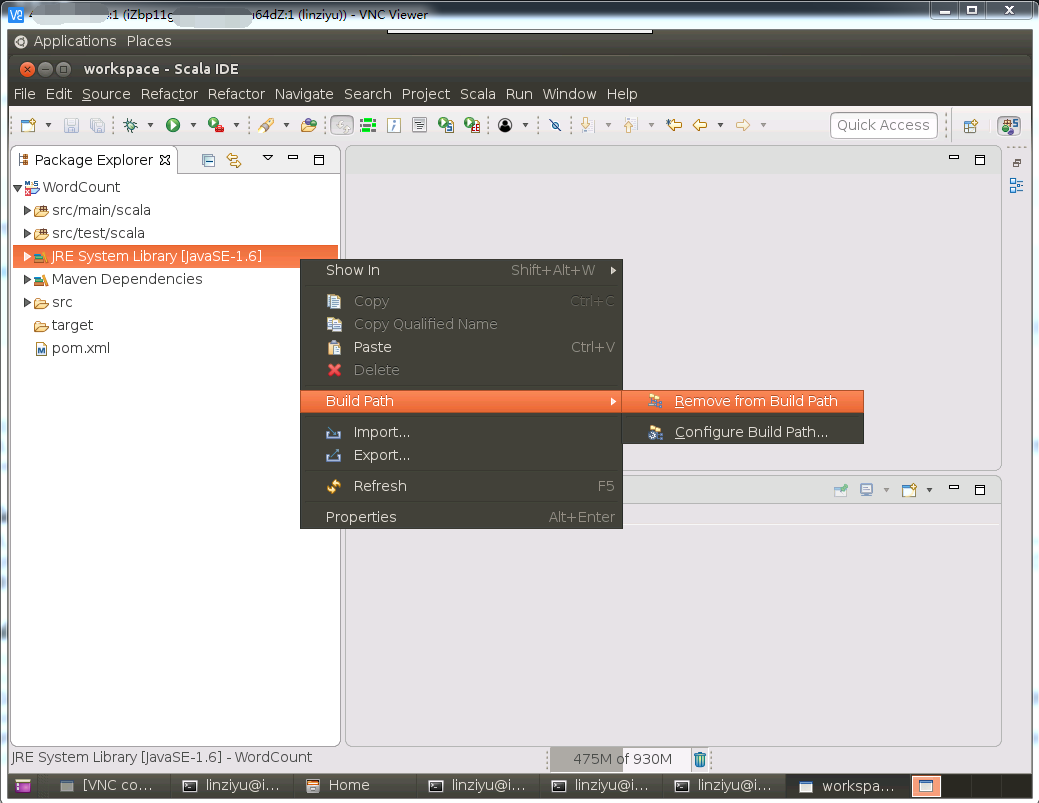
另外,我们发现,JDK的版本是“JavaSE-1.6”,版本不对,需要删除,进行更换,更换成我们之前已经在Ubuntu系统中安装成功的JDK1.8版本(因为Spark2.1.0必须要求JDK1.8以上版本)。同样,在如下图所示的界面中,在“JRE System Library[JavaSE-1.6]”上单击鼠标右键,在弹出的菜单中选择“Build Path”,在弹出的子菜单中选择“Remove from Build Path”,删除JavaSE-1.6版本。
然后,如下图所示,在WordCount工程名称上单击鼠标右键,在弹出的菜单中选择“Build Path”,在弹出的子菜单中选择“Add Libraries...”。
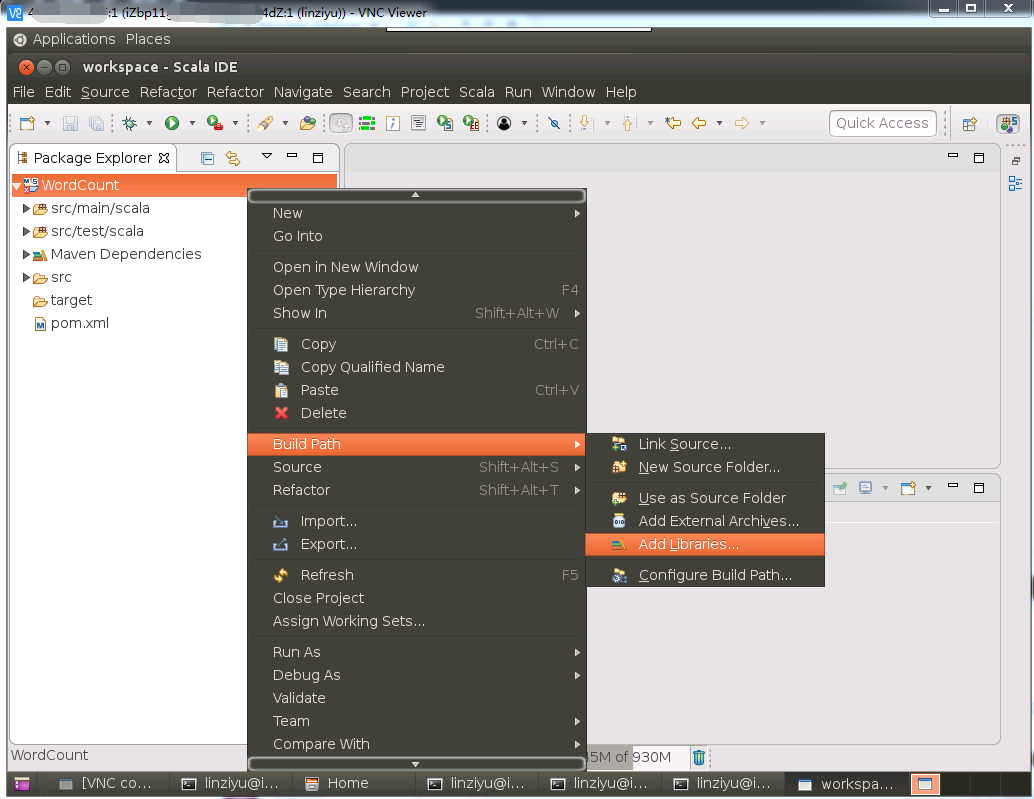
然后,弹出如下所示界面,选择“Scala Library”,然后,点击“Next”按钮。
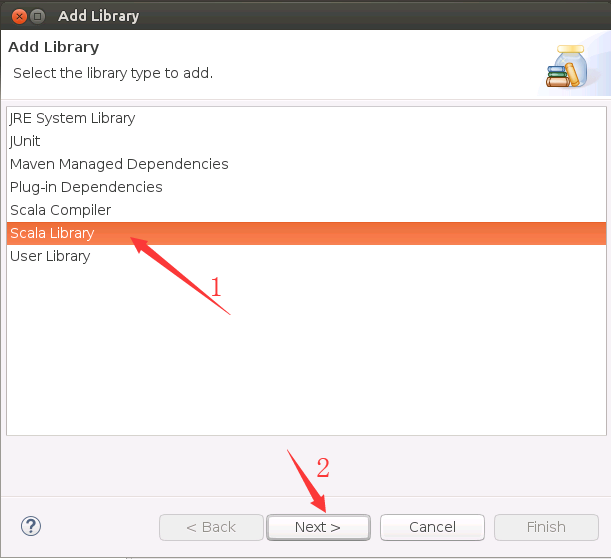
然后,弹出如下所示界面,选择“Latest 2.11 bundle(dynamic)”。
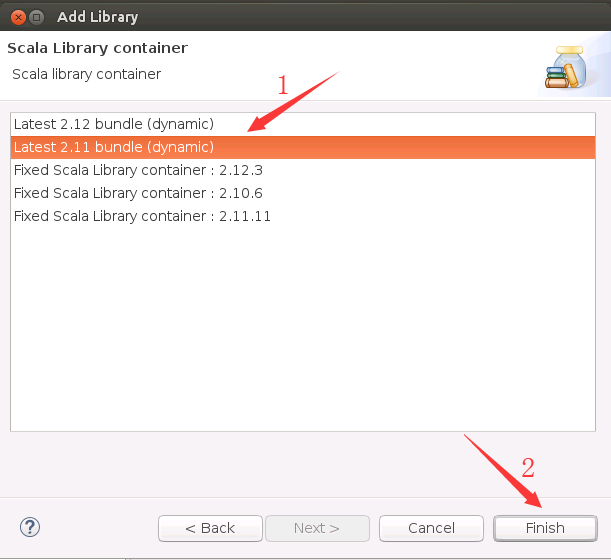
然后,返回到了如下所示的工程界面,可以看到“Scala Library Container[2.11.11]”,不是2.11.8。这个没有关系,程序是可以正常运行的。

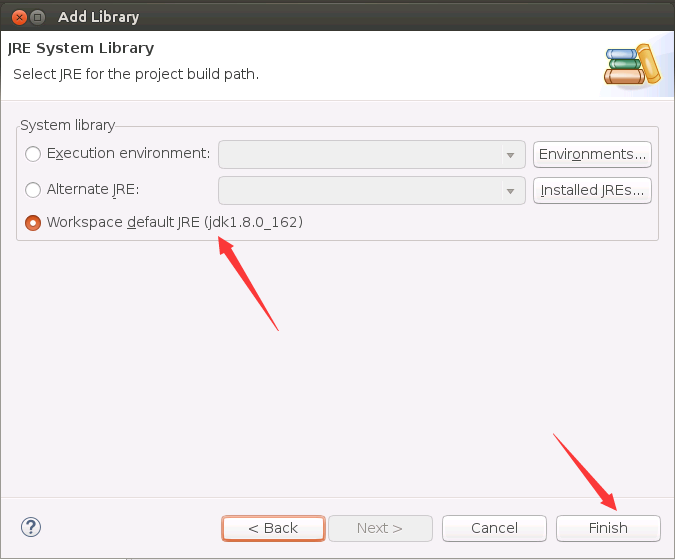
然后,再模仿上面的操作去添加JDK1.8。在WordCount工程名称上单击鼠标右键,在弹出的菜单中选择“Build Path”,在弹出的子菜单中选择“Add Libraries...”。弹出如下界面,在界面中选择“JRE System Library”,然后,点击“Next”按钮。

然后,会弹出如下界面,会默认选中“Workspace default JRE(jdk1.8.0_162)”,这是我们之前在Ubuntu系统中手动安装的,Eclipse会自动找到。然后,直接在界面中点击“Finish”按钮。
这时会返回到工程界面,如下图所示,可以看到,JDK1.8添加成功了。
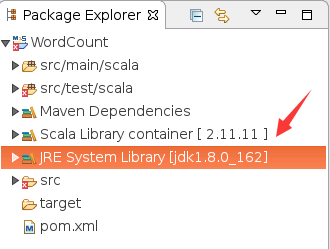
新建Scala代码文件
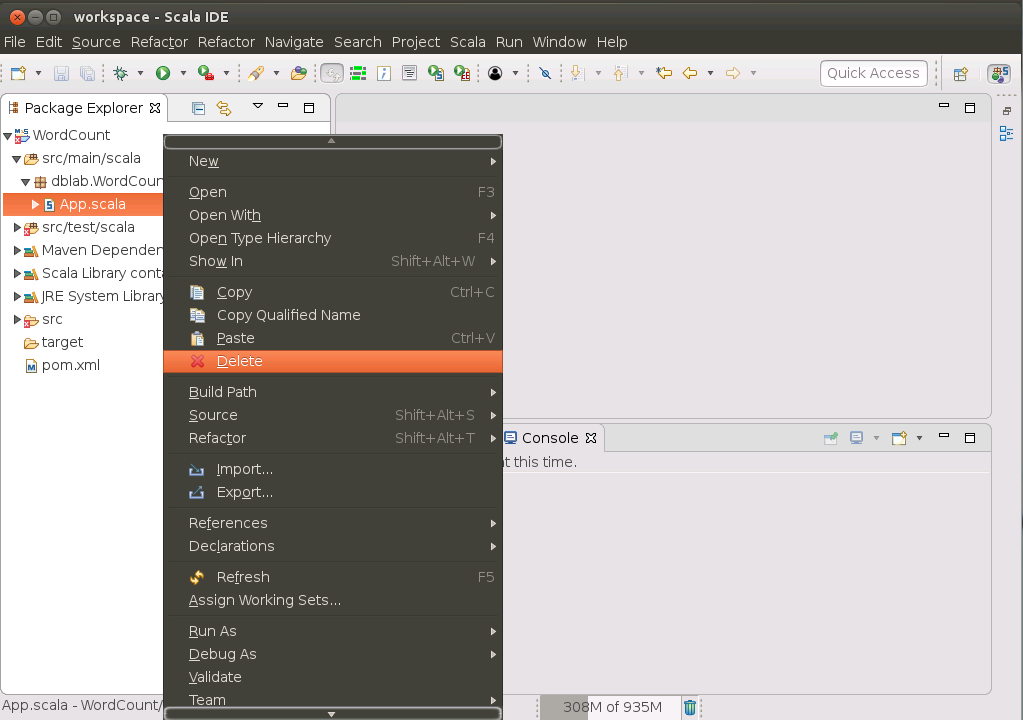
首先,把Eclipse自动创建的src/main/scala目录下的App.scala代码文件删除,如下图所示,在App.scala代码文件上单击鼠标右键,在弹出的菜单中选择“Delete”,在弹出的确认界面“Are you sure you want to delete file 'App.scala'”,中点击“OK”,就可以删除该文件。
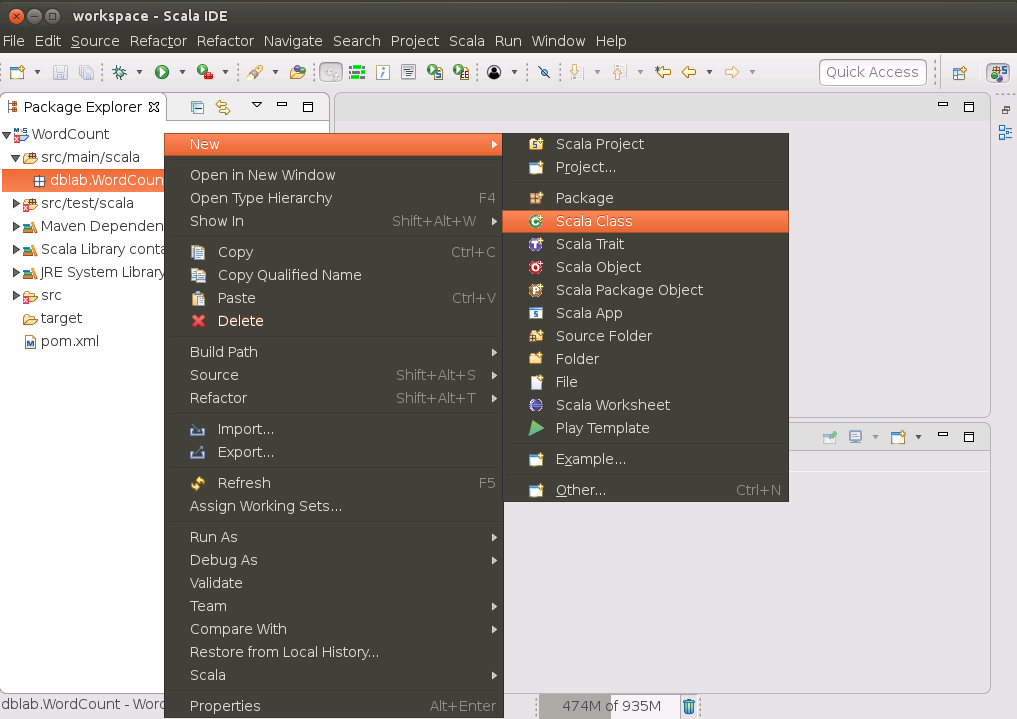
然后,在WordCount工程的src/main/scala目录下,新建一个名称为WordCount.scala的代码文件,方法是,如下图所示,在src/main/scala目录下的dblab.wordcount这个包(package)上面,单击鼠标右键,在弹出的菜单中选择New,然后,在弹出的菜单中选择“Scala Class”。
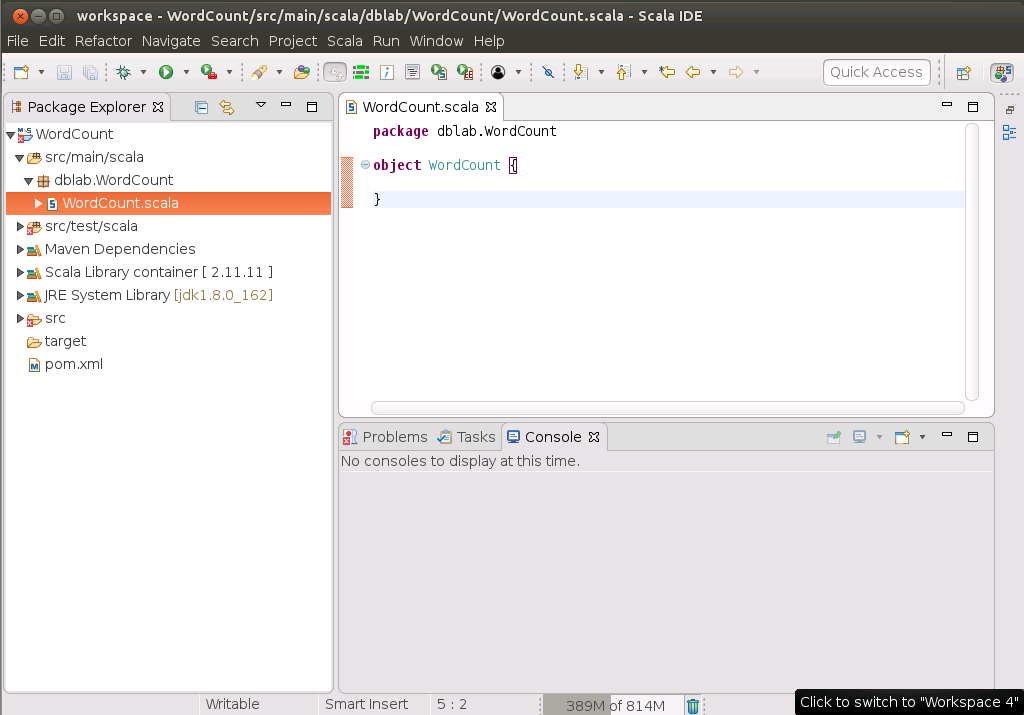
然后,会弹出如下界面,在“Kind”这个下拉列表框中,选择“Scala Object”(因为我们的WordCount.class中只会建立一个object对象,不会建class,如果以后你的程序要建class,那么这里就不要选择scala object,而是选择Scala Class)。然后,在Name这个文本框中给出单例对象的名称是“dblab.WordCount.WordCount”。然后,点击“Finish”按钮。

然后,就返回到了工程界面,如下图所示,Eclipse已经自动生成了一个代码文件WordCount.class,里面只包含了空框架。
然后,把WordCount.class里面的代码清空掉,把如下代码完全复制粘贴进去:
package dblab.WordCount
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf
object WordCount {
def main(args: Array[String]) {
val inputFile = "file:///usr/local/spark/mycode/wordcount/word.txt"
val conf = new SparkConf().setAppName("WordCount").setMaster("local[2]")
val sc = new SparkContext(conf)
val textFile = sc.textFile(inputFile)
val wordCount = textFile.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey((a, b) => a + b)
wordCount.foreach(println)
}
}
这段代码是对阿里云ECS的Ubuntu中的本地文件“/usr/local/spark/mycode/wordcount/word.txt”进行词频统计,如果该文件不存在,请你使用vim编辑器创建一个word.txt文件,并在里面随便输入几行英文单词,用于词频统计。
这时,工程界面的效果如下图所示:

修改pom.xml文件
接下来修改pom.xml文件。请在工程界面中,如下图所示,在pom.xml文件名上面右键单击鼠标,在弹出的菜单中选择“Open With”,在弹出的子菜单中选择“Text Editor”,打开pom.xml文件。
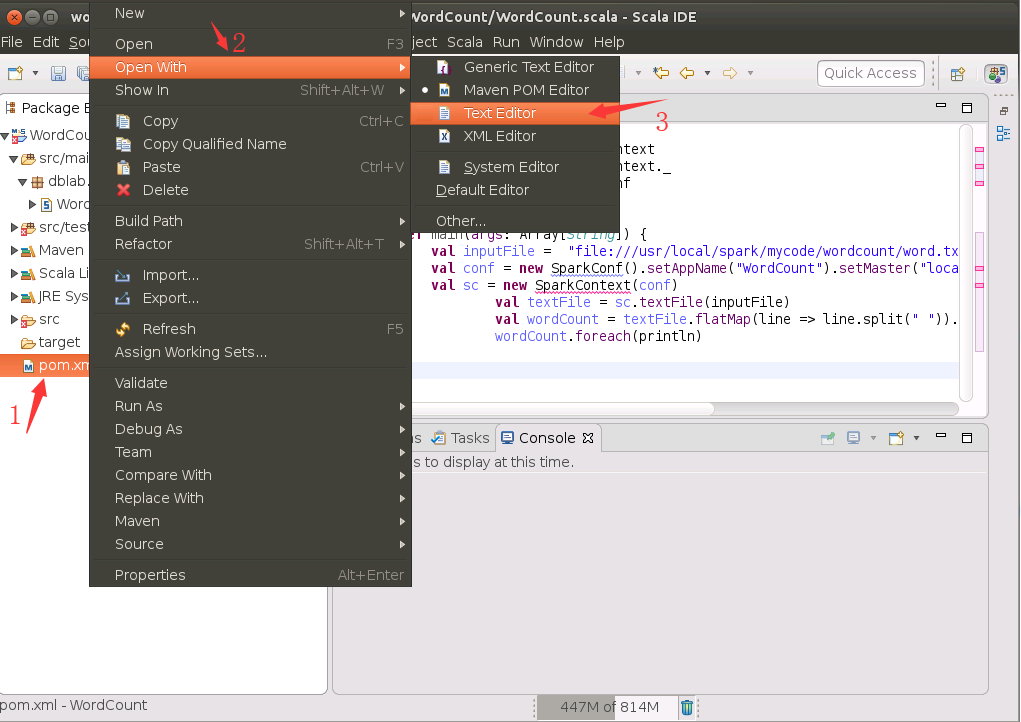
打开pom.xml以后的效果,如下图所示:
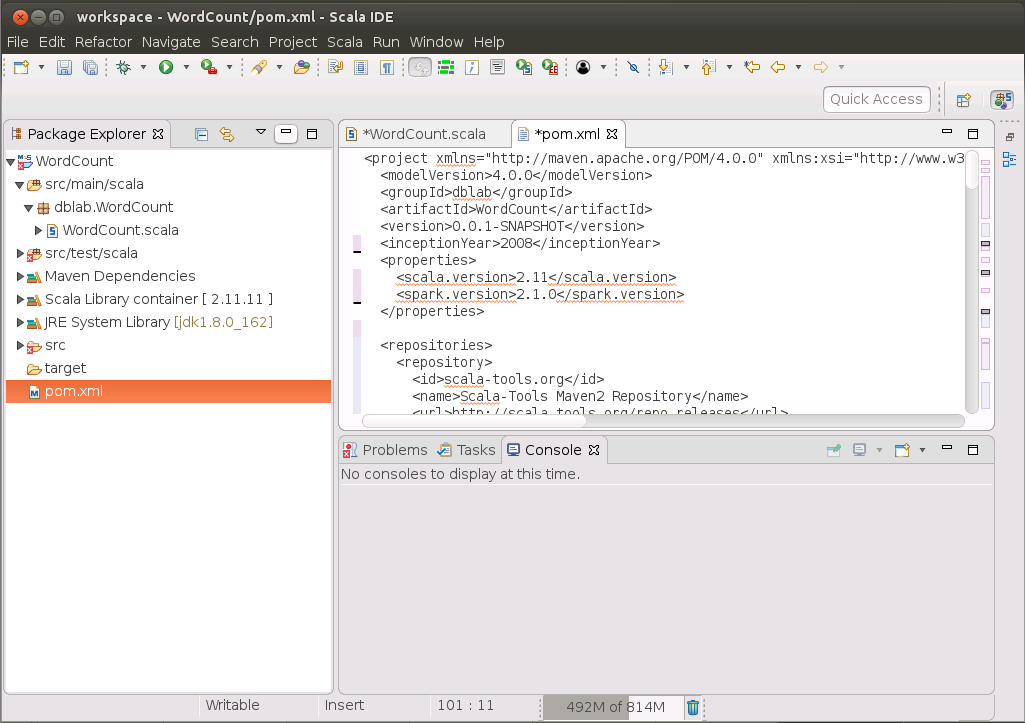
然后将pom.xml里的内容清空,复制黏贴如下代码:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>dblab</groupId>
<artifactId>WordCount</artifactId>
<version>0.0.1-SNAPSHOT</version>
<inceptionYear>2008</inceptionYear>
<properties>
<scala.version>2.11</scala.version>
<spark.version>2.1.0</spark.version>
</properties>
<repositories>
<repository>
<id>scala-tools.org</id>
<name>Scala-Tools Maven2 Repository</name>
<url>http://scala-tools.org/repo-releases</url>
</repository>
</repositories>
<pluginRepositories>
<pluginRepository>
<id>scala-tools.org</id>
<name>Scala-Tools Maven2 Repository</name>
<url>http://download.eclipse.org/releases/indigo/</url>
</pluginRepository>
</pluginRepositories>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.4</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.specs</groupId>
<artifactId>specs</artifactId>
<version>1.2.5</version>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<testSourceDirectory>src/test/scala</testSourceDirectory>
<plugins>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
<configuration>
<scalaVersion>${scala.version}</scalaVersion>
<args>
<arg>-target:jvm-1.5</arg>
</args>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-eclipse-plugin</artifactId>
<configuration>
<downloadSources>true</downloadSources>
<buildcommands>
<buildcommand>ch.epfl.lamp.sdt.core.scalabuilder</buildcommand>
</buildcommands>
<additionalProjectnatures>
<projectnature>ch.epfl.lamp.sdt.core.scalanature</projectnature>
</additionalProjectnatures>
<classpathContainers>
<classpathContainer>org.eclipse.jdt.launching.JRE_CONTAINER</classpathContainer>
<classpathContainer>ch.epfl.lamp.sdt.launching.SCALA_CONTAINER</classpathContainer>
</classpathContainers>
</configuration>
</plugin>
</plugins>
</build>
<reporting>
<plugins>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<configuration>
<scalaVersion>${scala.version}</scalaVersion>
</configuration>
</plugin>
</plugins>
</reporting>
</project>
编译WordCount代码
然后,如下图所示,在pom.xml这个代码窗口内的任意位置,单击鼠标右键,在弹出的菜单中选择“Run As”,在弹出的子菜单中选择“Mave Build...”。

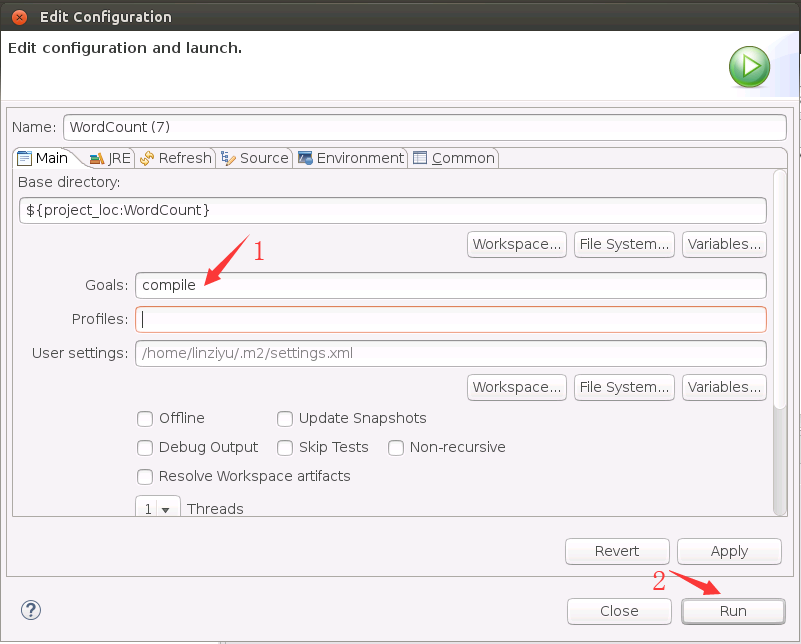
然后,会弹出如下界面,在Goals文本框中输入“compile”,然后,点击界面右下角的“Run”按钮。
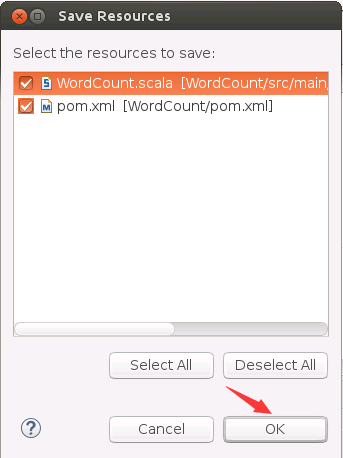
然后,会弹出如下界面,让你保存文件,点击“OK”按钮。
然后,Eclipse就开始编译,最后,可以得到如下所示的成功编译结果:

运行WordCount程序
如下图所示,打开WordCount.scala代码文件,在WordCount.scala代码窗口内的任意位置(不是pom.xml代码窗口内),单击鼠标右键,在弹出的菜单中选择“Run As”,在弹出的子菜单中选择“Scala Application”。
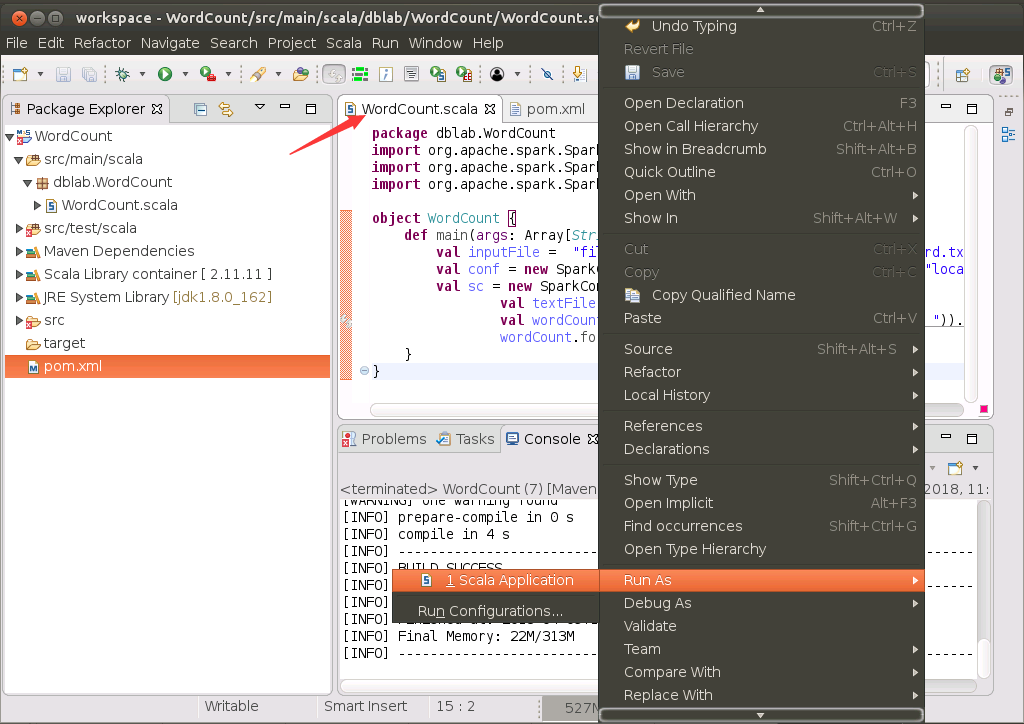
可能会弹出如下界面,说存在编译错误,实际上,之前我们已经编译成功,没有编译错误,所以,这里直接点击“YES”按钮。
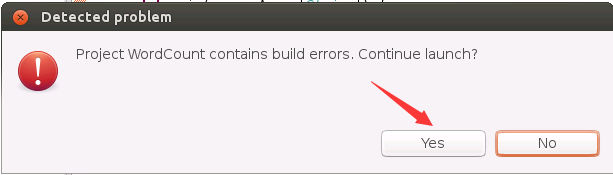
程序运行成功以后,会得到如下图所示结果:
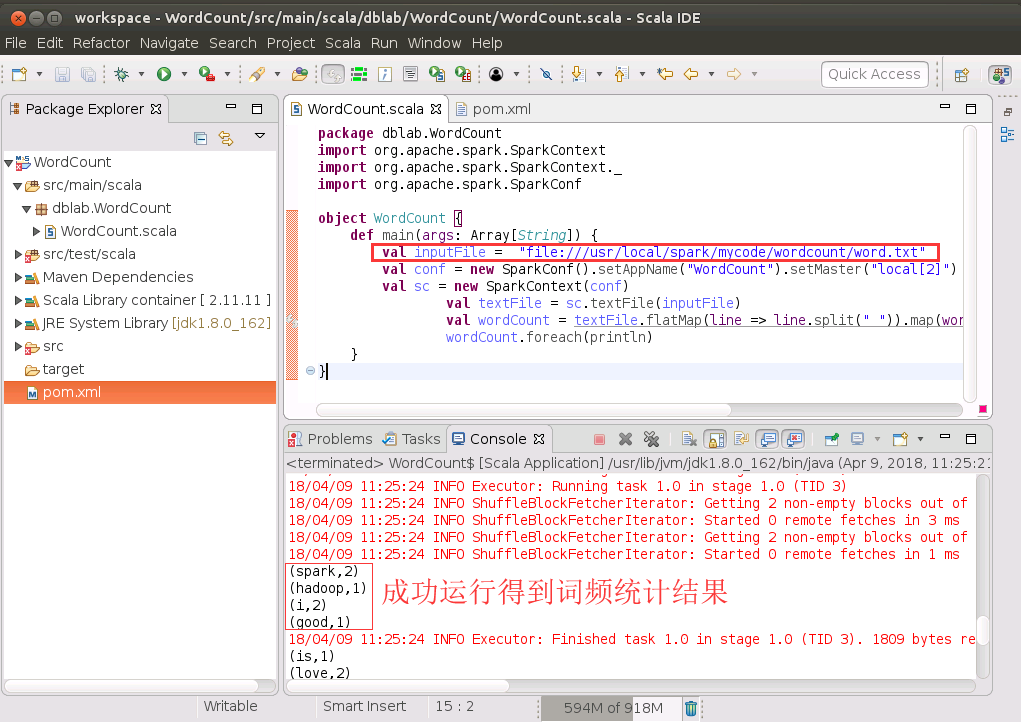
上面是对阿里云ECS实例的Ubuntu系统中的本地文件“/usr/local/spark/mycode/wordcount/word.txt”进行词频统计,下面我们更改一下文件路径,对HDFS文件进行词频统计(要确保你的HDFS已经开启运行),请在HDFS中创建一个词频文件"hdfs://192.168.1.106:9000/user/linziyu/word.txt"(注意,这里的192.168.1.106是阿里云ECS实例的私网IP地址,你的ECS实例的私网IP地址和这个不一样,要到阿里云控制台去查询一下),然后,把上面的WordCount.scala代码中的文件路径替换成HDFS文件word.txt。然后,在WordCount.scala代码窗口内的任意位置(不是pom.xml代码窗口内),单击鼠标右键,在弹出的菜单中选择“Run As”,在弹出的子菜单中选择“Scala Application”。
程序运行成功以后,会得到如下图所示结果:
打包WordCount程序生成JAR包
接着我们返回pom.xml的界面,如下图所示,在pom.xml代码窗口内的任意位置单击鼠标右键,在弹出的菜单选择“Run AS”,然后,在弹出的菜单选择“Maven install”。
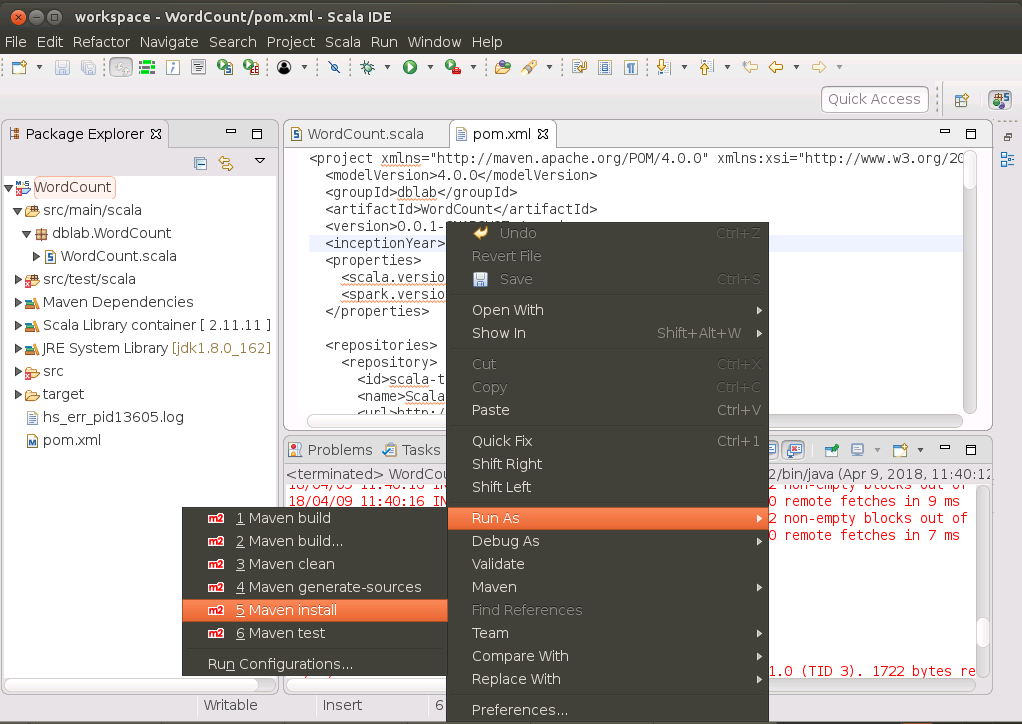
然后,就会发现打包过程出现错误,如下图所示:
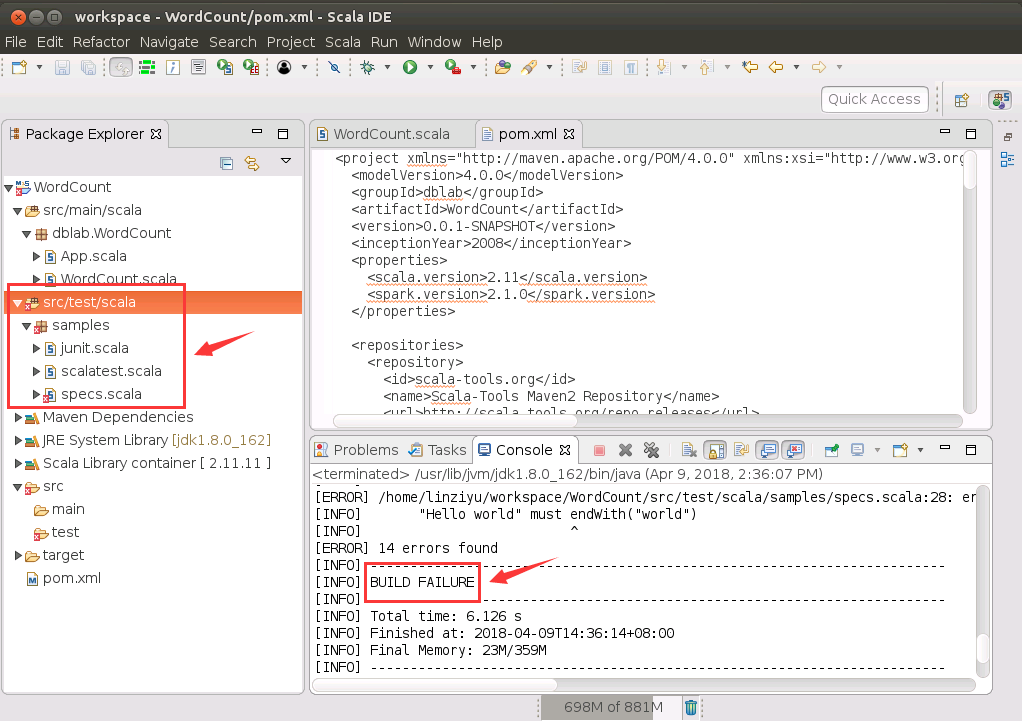
其实,这个打包错误,是由于目录“src/test/scala”下存在一些文件引起的,请在上图中左侧的“src/test/scala”这一行上面,单击鼠标右键,在弹出的菜单中选择“Delete”,后面又会弹出对话框,全部选择确认,就可以删除“src/test/scala”这个目录了,也就是删除了scala这个三级子目录。然后,再在pom.xml代码窗口内的任意位置单击鼠标右键,在弹出的菜单选择“Run AS”,然后,在弹出的菜单选择“Maven install”,就可以成功打包了,结果如下图所示:
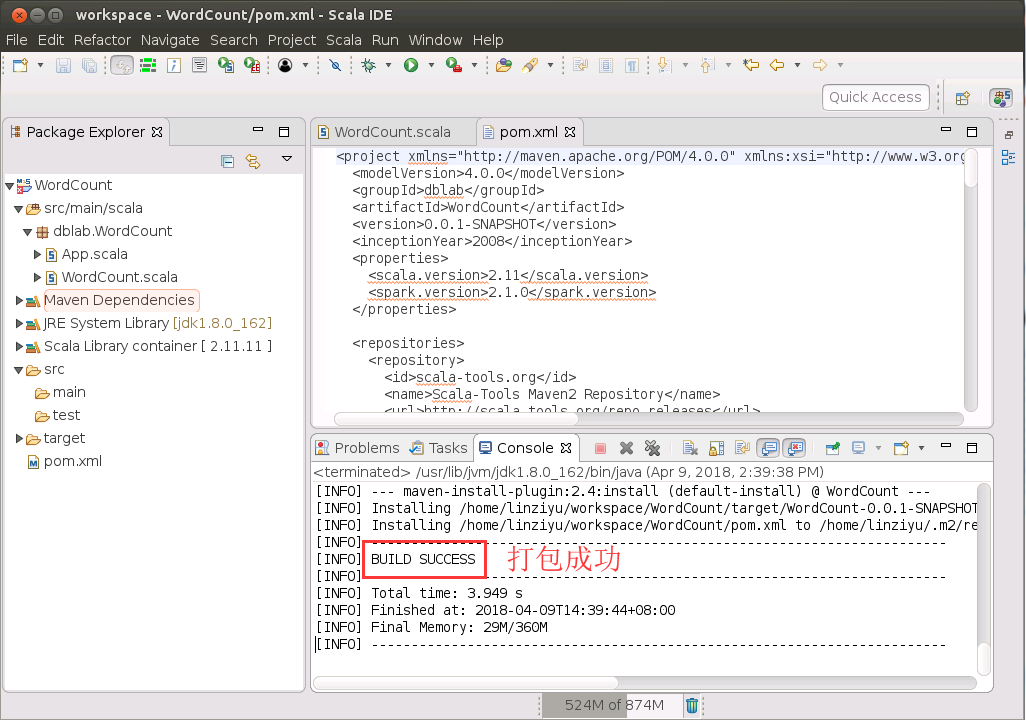
如下图所示,点击VNC连接界面的左上角的“Applications”,在弹出的子菜单点击“Accessories”,在弹出的子菜单选择“Files”,打开Ubuntu自带的文件夹管理系统:
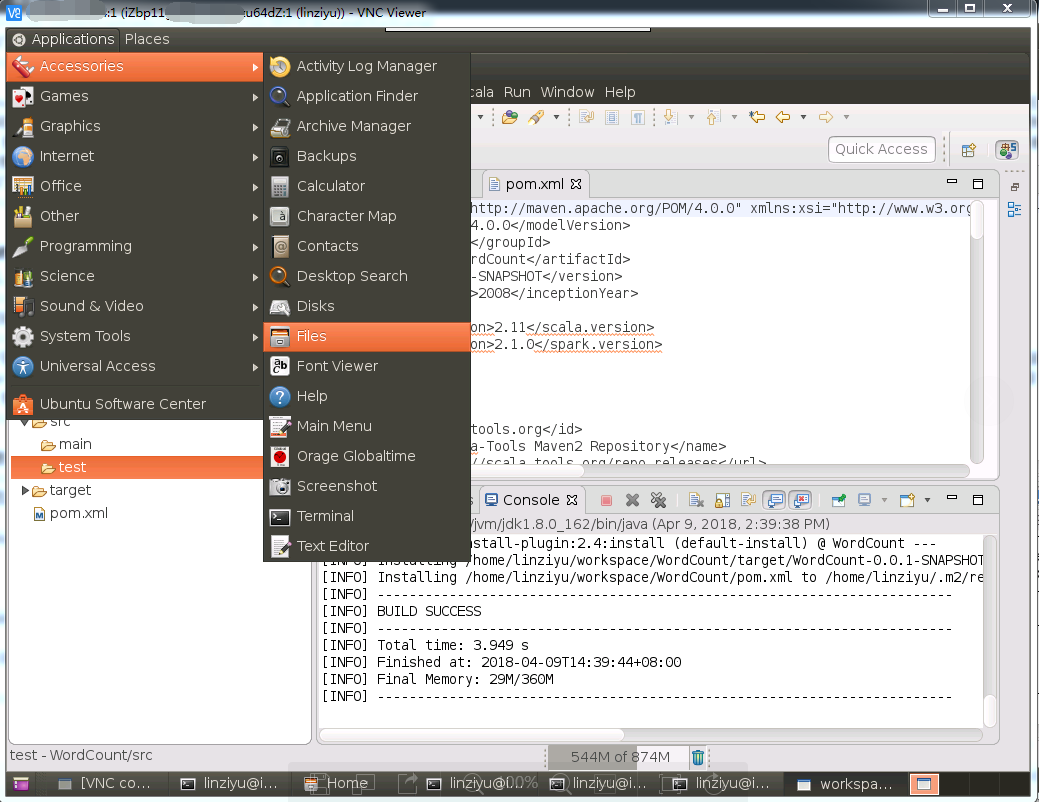
进入/home/linziyu/workspace/WordCount/target,这个目录,如下图所示,会看到WordCount-0.0.1-SNAPSHOT.jar,这个jar包就是Maven打包成功后得到的文件。
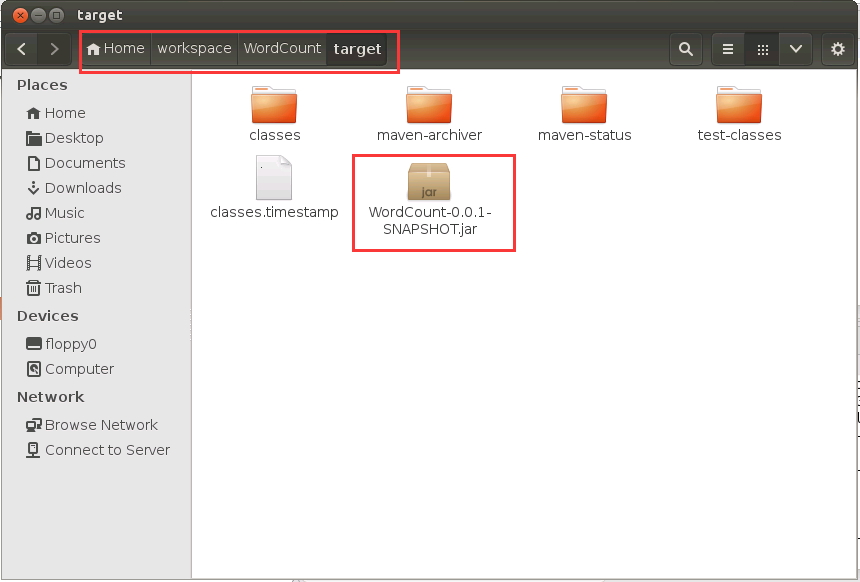
然后,由于Ubuntu系统的原因,如果jar包的路径太深,运行时,很可能会出现找不到类的异常,所以我们可以把这个包移动到常用的较浅的目录下,请在Ubuntu的命令行终端中执行如下Shell命令:
cd ~
sudo cp /home/linziyu/workspace/WordCount/target/WordCount-0.0.1-SNAPSHOT.jar /home/linziyu
接着运行以下命令:
/usr/local/spark/bin/spark-submit --class "dblab.WordCount.WordCount" /home/linziyu/WordCount-0.0.1-SNAPSHOT.jar
出现如下结果,就说明你在终端下已经成功运行了scala的WordCount程序。
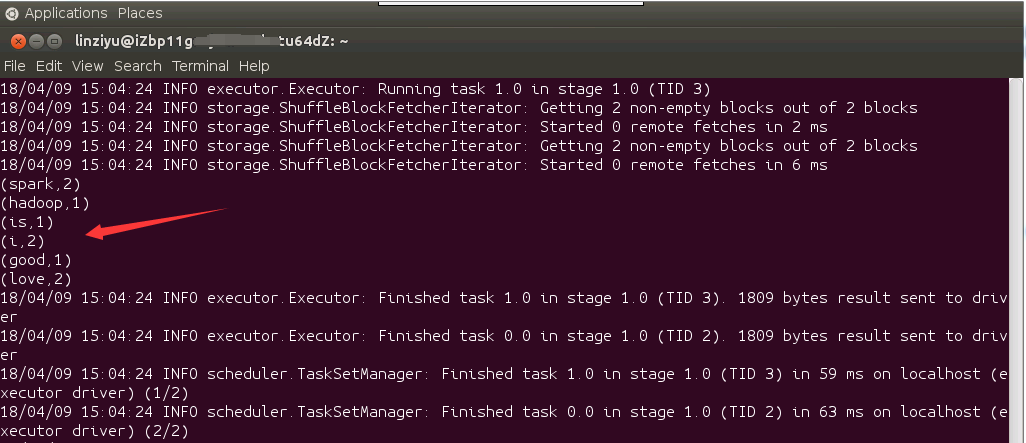
最后的一点改进
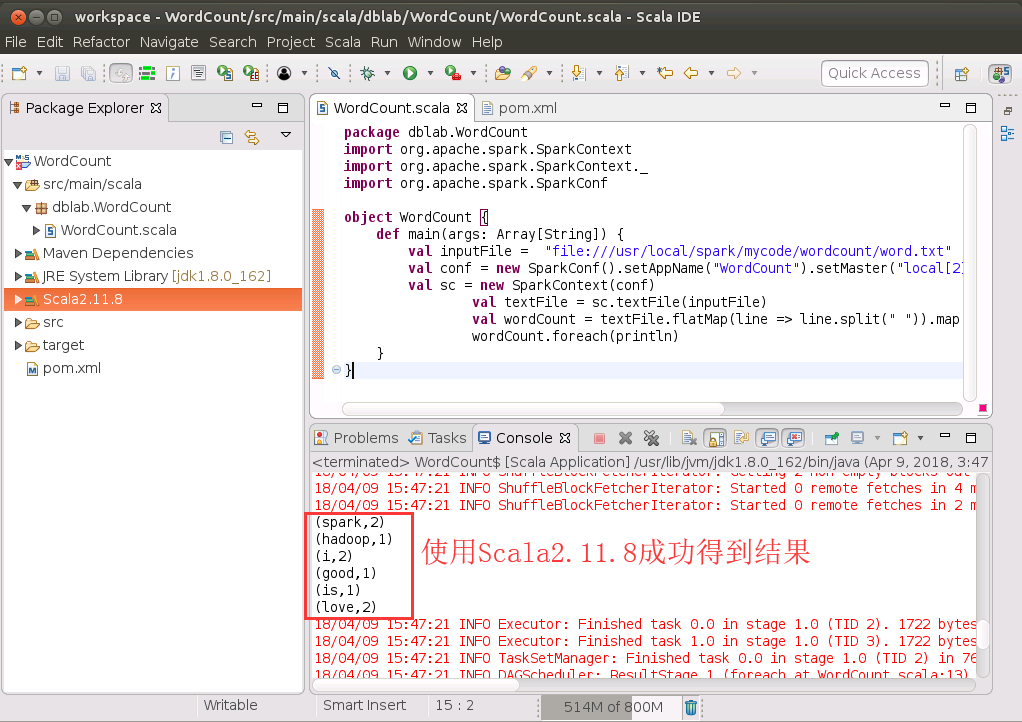
上面我们在添加Scala库时,使用的是Eclipse自带的2.11.11版本的库文件,如果一定要把库文件更换成Scala2.11.8,也是可以的。下面就来操作一下。
首先,按照本博客之前介绍的方法,把当前工程中的Scala2.11.11版本的库文件移除,方法是,在“Scala Library Container[2.11.11]”上面单击鼠标右键,在弹出的菜单中选择“Build Path”,在弹出的子菜单中选择“Remove from Build Path”,删除Scala2.11.11版本的库文件。
然后,把我们之前已经在Ubuntu中安装的Scala2.11.8的库文件,人工导入到Eclipse中。
如下图所示,在WordCount工程名称上单击鼠标右键,在弹出的菜单中选择“Build Path”,在弹出的子菜单中选择“Add Libraries...”。
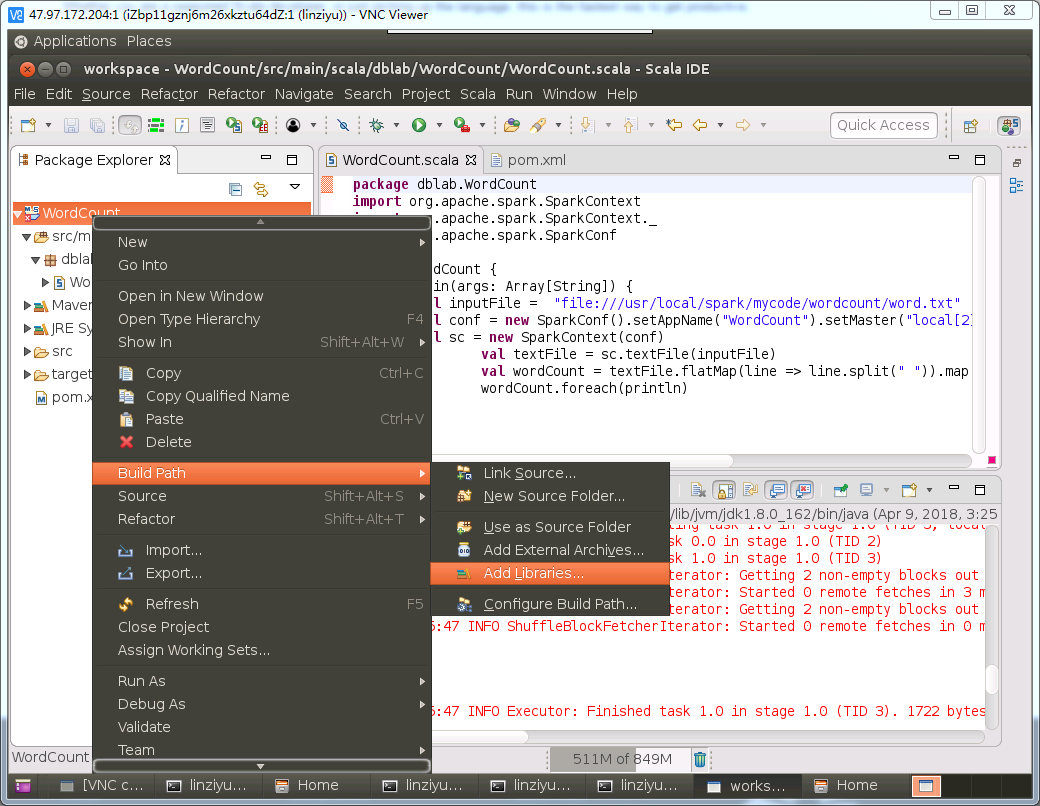
然后,会弹出如下界面,选择“User Library”,然后点击“Next”按钮。
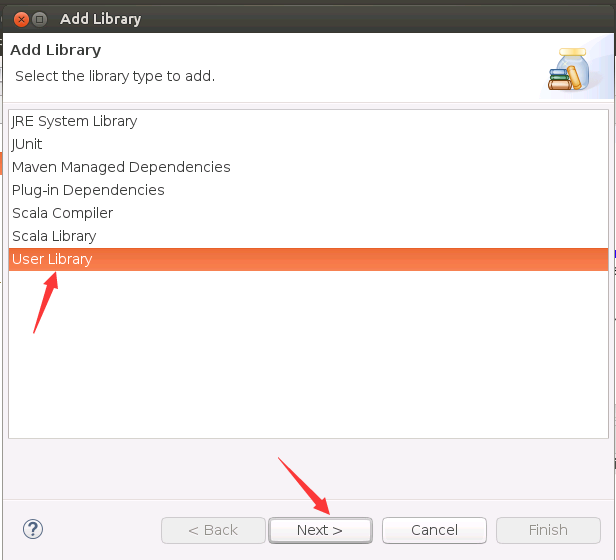
然后,会弹出如下界面,点击右侧的“User Libraries”按钮。
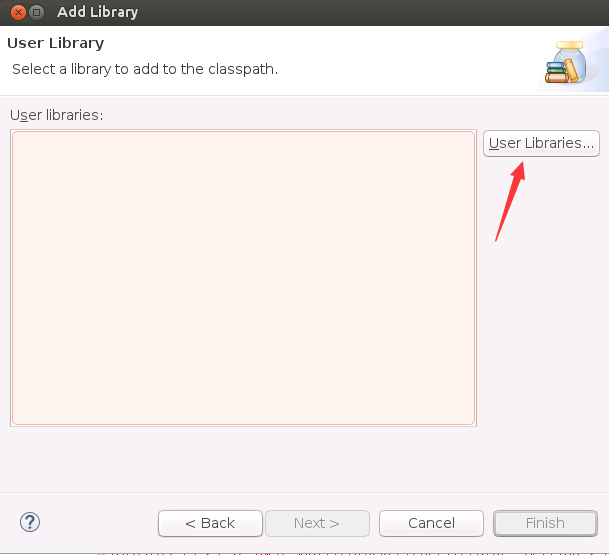
然后,会弹出如下界面,点击右侧的“New”按钮。
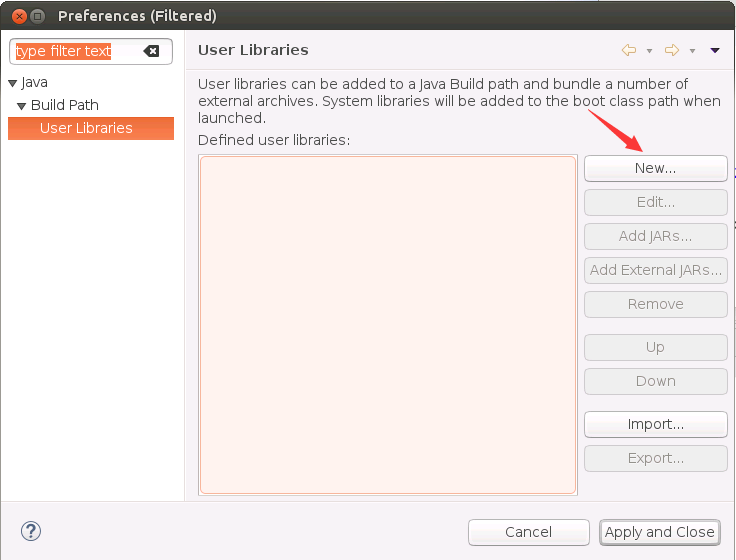
然后,会弹出如下界面,在“User library name”文本框中输入“Scala2.11.8”,这是给库起个名字,以后,就可以直接使用这个名字来加载库文件,然后,点击右侧的“OK”按钮。
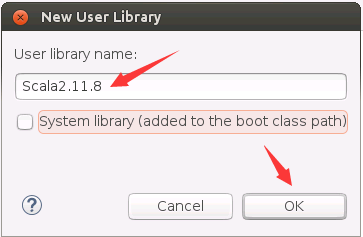
然后,会弹出如下界面,点击右侧的“Add External JARs...”按钮。
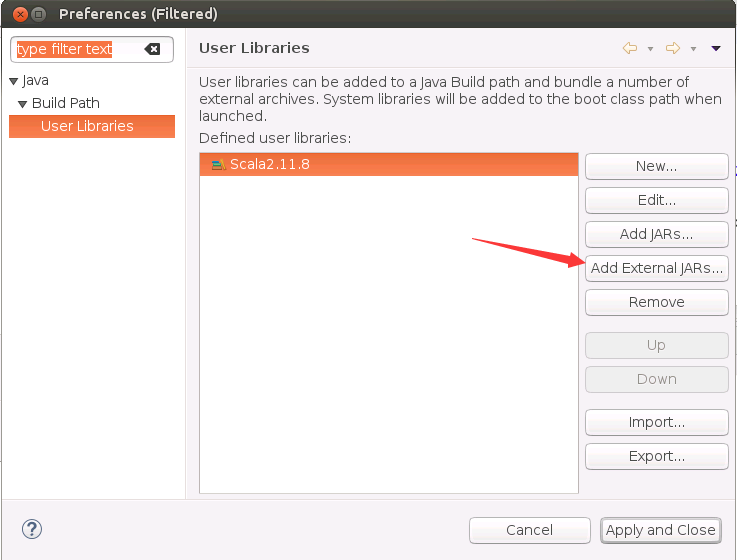
- 然后,会弹出如下界面,请找到我们之前已经在Ubuntu中安装的Scala2.11.8的目录,也就是目录“/usr/local/scala”,然后,进入“/usr/local/scala/lib”目录,选中该目录下的所有jar包,点击界面底部的“OK”按钮。

然后,会弹出如下界面,点击底部的“Apply and Close”按钮。
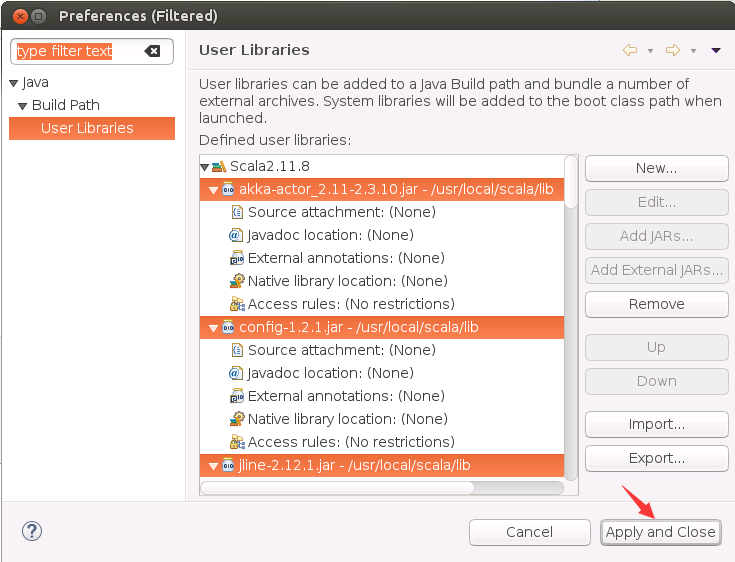
然后,会弹出如下界面,点击底部的“Finish”按钮。

然后,按照本博客中之前介绍的方法,在pom.xml这个代码窗口内的任意位置,单击鼠标右键,在弹出的菜单中选择“Run As”,在弹出的子菜单中选择“Mave Build...”,然后在弹出的界面中,在Goals文本框中输入“compile”,然后,点击界面右下角的“Run”按钮,开始编译程序,和之前一样,会编译成功。
然后,我们就可以运行程序,如下图所示,在WordCount.scala代码窗口内的任意位置(不是pom.xml代码窗口内),单击鼠标右键,在弹出的菜单中选择“Run As”:
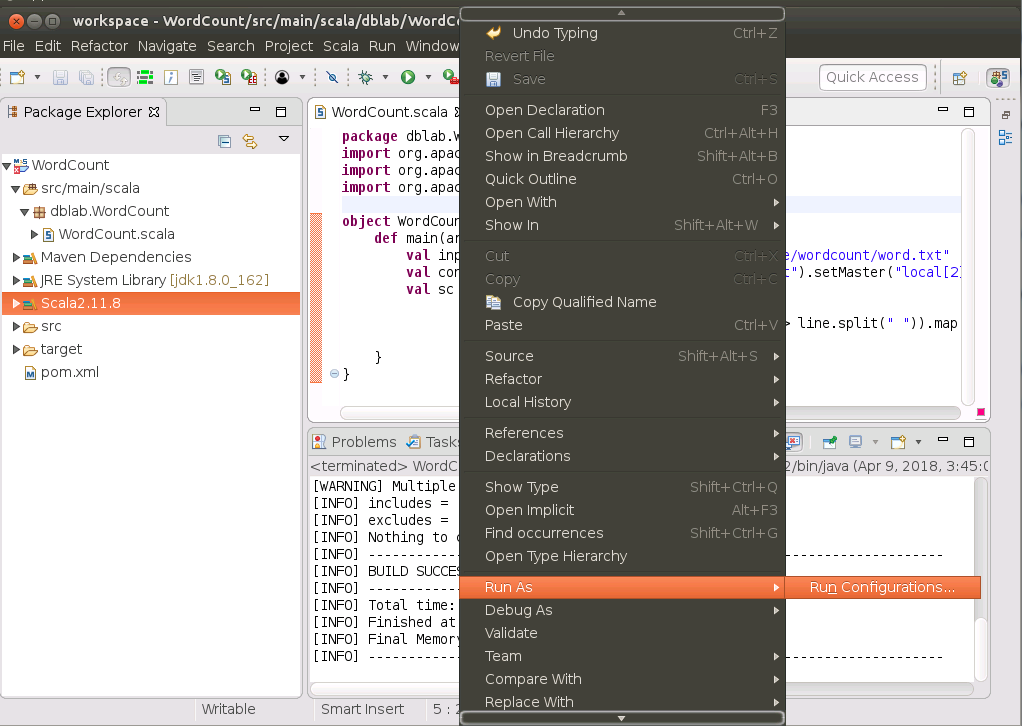
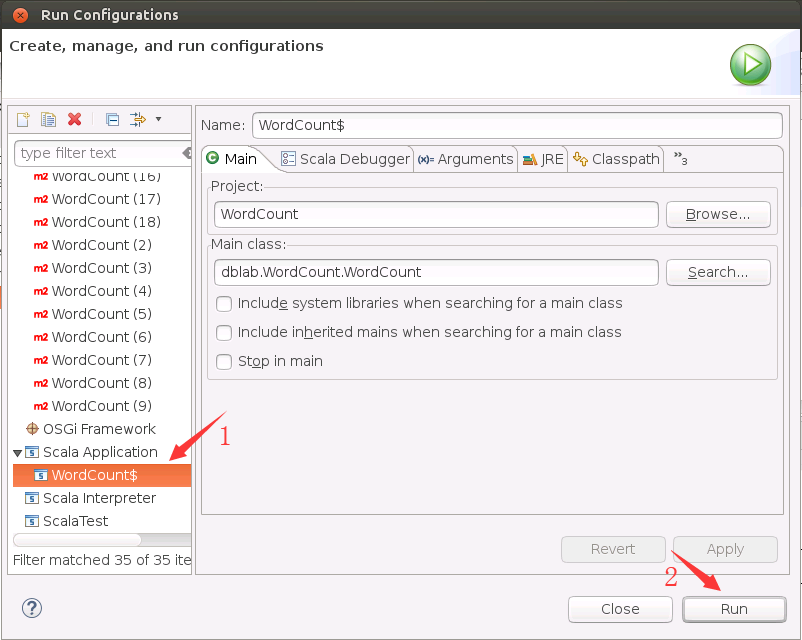
在弹出的子菜单中,如果存在“Scala Application”,就直接选择这个选项,如果没有这个选项,只有“Run Configurations...”,那么,就点击“Run Configurations...”,会出现如下界面,可以在界面左侧选择“Scala Application”,然后选择“WordCount$”,最后,点击右下角的“Run”按钮,就可以顺利运行得到结果了。
运行成功以后,可以得到如下所示结果: